5. Kernel Learning#
Kernel learning is a way to transform features in either classification or regression problems. Recall in regression, we have the following model equation:
where \(\vec{x}\) is our feature vector of dimension \(D\). In kernel learning, we transform our feature vector from dimension \(D\) features to distances to training data points of dimension \(N\), where \(N\) is the number of training data points:
where \(\left<\cdot\right>\) is the distance between two feature vectors and \(\vec{x}_i\) is the \(i\)th training data point. \(\vec{x}\) is the function argument whereas \(\vec{x}_i\) are known values.
Audience & Objectives
This chapter builds on Regression & Model Assessment and Classification. After completing this chapter, you should be able to
Distinguish between primal and dual form
Choose when kernel learning could be beneficial
Understand the principles of training curves and the connection between training size and feature number
One of the consequences of this transformation is that our training weight vector, \(\vec{w}\), no longer depends on the number of features. Instead the number of weights depends on the number of training data points. This is the reason we use kernel learning. You might have few training data points but large feature vectors (\(N < D\)). By using the kernel formulation, you’ll reduce the number of weights. It might also be that your feature space is hard to model with a linear equation, but when you view it as distances from training data it becomes linear (often \(N > D\)). Finally, it could be that your feature vector is infinite dimensional (i.e., it is a function not a vector) or for some reason you cannot compute it. In kernel learning, you only need to define your kernel function \(\left<\cdot\right>\) and never explicitly work with the feature vector.
The distance function is called a kernel function \(\left<\cdot\right>\). A kernel function is a binary function (takes two arguments) that outputs a scalar and has the following properties:
Positive: \(\left<x, x'\right> \geq 0\)
Symmetric: \(\left<x, x'\right> = \left<x', x \right>\)
Point-separating: \(\left<x, x'\right> = 0\) if and only if \(x = x'\)
The classic kernel function example is \(L_2\) norm (Euclidean distance): \(\left<\vec{x}, \vec{x}'\right>=\sqrt{\sum^D_i (x_i - x_i^{'})^2}\). Some of the most interesting applications of kernel learning though are when \(x\) is not a vector, but a function or some other structured object.
Primal & Dual Form
Dual Form is what some call our model equation when it uses the kernels: \(\hat{y} = \sum_i^N w_i \left<\vec{x}, \vec{x}_i\right>+ b\). To distinguish from the dual form, you can also refer to the usual model equation as the Primal Form \(\hat{y} = \vec{w}\vec{x} + b\). It also sounds cool.
Kernel learning is a widely-used approach for learning potential energy functions and force fields in molecular modeling [RTMullerVL12, SSAB20].
5.1. Solubility Example#
Let’s revisit the solubility AqSolDB[SKE19] dataset from Regression & Model Assessment. Recall it has about 10,000 unique compounds with measured solubility in water (label) and 17 molecular descriptors (features).
5.2. Running This Notebook#
Click the above to launch this page as an interactive Google Colab. See details below on installing packages.
Tip
To install packages, execute this code in a new cell.
!pip install dmol-book
If you find install problems, you can get the latest working versions of packages used in this book here
As usual, the code below sets-up our imports.
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import jax.numpy as jnp
import jax
import dmol
# soldata = pd.read_csv('https://dataverse.harvard.edu/api/access/datafile/3407241?format=original&gbrecs=true')
soldata = pd.read_csv(
"https://github.com/whitead/dmol-book/raw/main/data/curated-solubility-dataset.csv"
)
features_start_at = list(soldata.columns).index("MolWt")
feature_names = soldata.columns[features_start_at:]
np.random.seed(0)
# Split into train(80) and test(20)
N = len(soldata)
split = int(N * 0.8)
shuffled = soldata.sample(N, replace=False)
train = shuffled[:split]
test = shuffled[split:]
# standardize the features using only train
test[feature_names] -= train[feature_names].mean()
test[feature_names] /= train[feature_names].std()
train[feature_names] -= train[feature_names].mean()
train[feature_names] /= train[feature_names].std()
5.3. Kernel Definition#
We’ll start by creating our kernel function. Our kernel function does not need to be differentiable. In contrast to the functions we see in deep learning, we can use sophisticated and non-differentiable functions in kernel learning. For example, you could use a two-component molecular dynamics simulation to compute the kernel between two molecules. We’ll still implement our kernel functions in JAX for this example because it is efficient and consistent. Remember our kernel should take two feature vectors and return a scalar. In our example, we will simply use the \(L_2\) norm. There is one small change: dividing by the dimension. This makes our kernel output magnitude is independent of the number of dimensions of \(x\). Other options for kernels for dense vectors are \(1 - \) cosine similarity (dot product) or Mahalanobis distance.
Choosing a kernel function is an open question for molecules. You can work with the molecular structure directly with a variety of ideas. You can use Graph Neural Networks to convert molecules into vectors and use any of the vector kernels above. You can work with fingerprints (vectors of bits) from cheminformatics libraries like Rdkit and compare such vectors with Tanimoto similarity [RGMS22, YHFS22].
def kernel(x1, x2):
return jnp.sqrt(jnp.mean((x1 - x2) ** 2))
5.4. Model Definition#
Now we define our regression model equation in the dual form. Remember that our function must always take the training data in to compute the distance to a new given point. We will use the batch feature of JAX to compute all the kernels simultaneously for our new point.
def model(x, train_x, w, b):
# make vectorized version of kernel
vkernel = jax.vmap(kernel, in_axes=(None, 0), out_axes=0)
# compute kernel with all training data
s = vkernel(x, train_x)
# dual form
yhat = jnp.dot(s, w) + b
return yhat
# make batched version that can handle multiple xs
batch_model = jax.vmap(model, in_axes=(0, None, None, None), out_axes=0)
5.5. Training#
We now have trainable weights and a model equation. To begin training, we need to define a loss function and compute its gradient. We’ll use mean squared error as usual for the loss function. We can use regularization, as we saw previously, but will skip it for now.
@jax.jit
def loss(w, b, train_x, x, y):
return jnp.mean((batch_model(x, train_x, w, b) - y) ** 2)
loss_grad = jax.grad(loss, (0, 1))
# convert from pandas dataframe to numpy arrays
train_x = train[feature_names].values
train_y = train["Solubility"].values
test_x = test[feature_names].values
test_y = test["Solubility"].values
We’ve defined our loss and split our data into training/testing. Now we will set-up the training parameters, including breaking up our training data into batches. An epoch is one iteration through the whole dataset.
eta = 1e-5
batch_size = 32
epochs = 10
# reshape into batches
batch_num = train_x.shape[0] // batch_size
# first truncate data so it's whole nubmer of batches
trunc = batch_num * batch_size
train_x = train_x[:trunc]
train_y = train_y[:trunc]
# split into batches
x_batches = train_x.reshape(-1, batch_size, train_x.shape[-1])
y_batches = train_y.reshape(-1, batch_size)
# make trainable parameters
# w = np.random.normal(scale = 1e-30, size=train_x.shape[0])
w = np.zeros(train_x.shape[0])
b = np.mean(train_y) # just set to mean, since it's a good first guess
You may notice our learning rate, \(\eta\), is unusually low at \(10^{-5}\). It’s because each training data point, for which we have about 8,000, contributes to the final \(\hat{y}\). Thus if we take a large training step, it is can create very big changes to \(\hat{y}\).
loss_progress = []
test_loss_progress = []
for _ in range(epochs):
# go in random order
for i in np.random.randint(0, batch_num - 1, size=batch_num):
# update step
x = x_batches[i]
y = y_batches[i]
loss_progress.append(loss(w, b, train_x, x, y))
test_loss_progress.append(loss(w, b, train_x, test_x, test_y))
grad = loss_grad(w, b, train_x, x, y)
w -= eta * grad[0]
b -= eta * grad[1]
plt.plot(loss_progress, label="Training Loss")
plt.plot(test_loss_progress, label="Testing Loss")
plt.xlabel("Step")
plt.yscale("log")
plt.legend()
plt.ylabel("Loss")
plt.show()
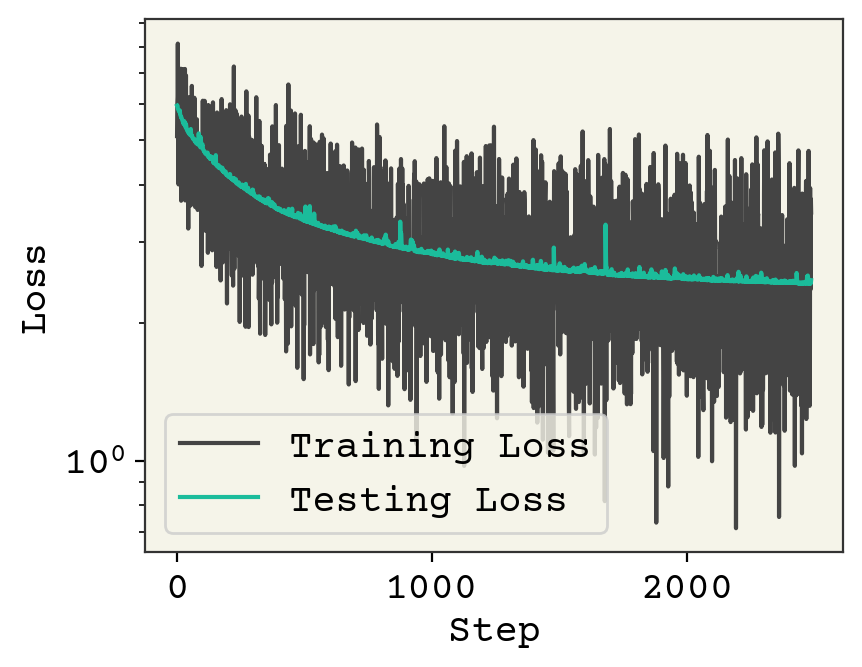
One small change from previous training loops is that we randomized our batches in the for loop.
yhat = batch_model(test_x, train_x, w, b)
plt.plot(test_y, test_y)
plt.plot(test_y, yhat, ".")
plt.text(min(y) + 1, max(y) - 2, f"correlation = {np.corrcoef(test_y, yhat)[0,1]:.3f}")
plt.text(min(y) + 1, max(y) - 3, f"loss = {np.sqrt(np.mean((test_y - yhat)**2)):.3f}")
plt.title("Testing Data")
plt.show()
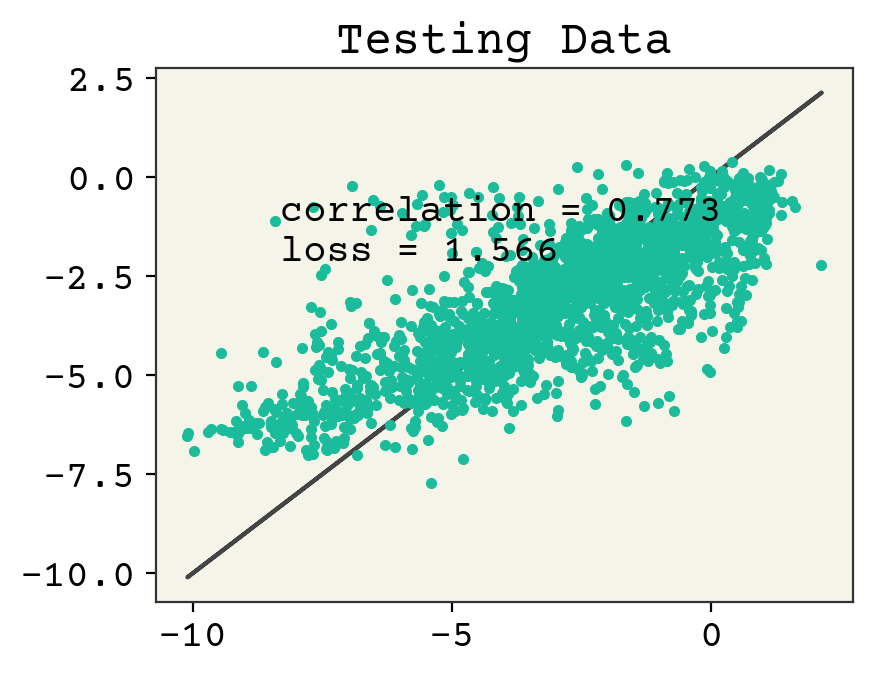
We can see our results show underfitting. As usual, I want to make this code execute fast so I have not done many epochs. You can increase the epoch number and watch the loss and correlation improve over time.
5.6. Regularization#
You’ll notice that our trainable parameter number, by design, is equal to the number training data points. If we were to use a direct computation of the fit coefficients with a pseudo-inverse, we could run into problems because of this. Thus, most people add an additional regularization term to both make matrix algebra solutions tractable and because it seems wise with the large number of trainable parameters. Just like we saw in linear regression, L1 regression is known as Lasso Ridge Regression and L2 is known as Kernel Ridge Regression. Remember that L1 zeros-out specific parameters which was useful for interpreting the importance of features in linear regression. However, in the kernel setting this would only zero-out specific training data points and thus provides no real insight(usually, see Explaining Predictions). Kernel ridge regression is thus more popular in the kernel setting.
5.7. Training Curves#
The bias-variance trade-off from Regression & Model Assessment showed how increasing model complexity could reduce model bias (more expressive and able to fit data better) at the cost of increased model variance (more sensitive to training data choice and amount). The model complexity was controlled by adjusting feature number. In kernel learning, we cannot control feature number because it is always equal to the number of training data points. Thus, we can only control hyperparameters like the choice of kernel, regularization, learning rate, etc. To assess these effects, we usually do not only compute test loss because that is highly-connected to the amount of training data you have. More training data means more sophisticated models and thus lower loss. So it is common in kernel learning especially to show how the test-loss changes a function of training data amount. These are presented as log-log plots due to the large magnitude changes in these. These are called training curves (or sometimes learning curves). Training curves can be applied broadly in ML and deep learning, but you’ll most often see them in kernel learning.
Let’s revisit our solubility model and compare L1 and L2 regularization with a training curve. Note that this code is very slow because we must compute \(M\) models, where \(M\) is the number of points we want on our training curve. To keep things efficient for this textbook, I’ll use few points on the curve.
First, we’ll turn our training procedure into a function.
def fit_model(loss, npoints, eta=1e-6, batch_size=16, epochs=25):
sample_idx = np.random.choice(
np.arange(train_x.shape[0]), replace=False, size=npoints
)
sample_x = train_x[sample_idx, :]
sample_y = train_y[sample_idx]
# reshape into batches
batch_num = npoints // batch_size
# first truncate data so it's whole nubmer of batches
trunc = batch_num * batch_size
sample_x = sample_x[:trunc]
sample_y = sample_y[:trunc]
# split into batches
x_batches = sample_x.reshape(-1, batch_size, sample_x.shape[-1])
y_batches = sample_y.reshape(-1, batch_size)
# get loss grad
loss_grad = jax.grad(loss, (0, 1))
# make trainable parameters
# w = np.random.normal(scale = 1e-30, size=train_x.shape[0])
w = np.zeros(sample_x.shape[0])
b = np.mean(sample_y) # just set to mean, since it's a good first guess
for _ in range(epochs):
# go in random order
for i in np.random.randint(0, batch_num - 1, size=batch_num):
# update step
x = x_batches[i]
y = y_batches[i]
grad = loss_grad(w, b, sample_x, x, y)
w -= eta * grad[0]
b -= eta * grad[1]
return loss(w, b, sample_x, test_x, test_y)
# test it out
fit_model(loss, 256)
Array(5.928047, dtype=float32)
Now we’ll create L1 and L2 version of our loss. We must choose the strength of the regularization. Since our weights are less than 1, I’ll choose much stronger regularization for the L2. These are hyperparameters though and you can adjust them to improve your fit.
@jax.jit
def loss_l1(w, b, train_x, x, y):
return jnp.mean((batch_model(x, train_x, w, b) - y) ** 2) + 1e-2 * jnp.sum(
jnp.abs(w)
)
@jax.jit
def loss_l2(w, b, train_x, x, y):
return jnp.mean((batch_model(x, train_x, w, b) - y) ** 2) + 1e2 * jnp.sum(w**2)
And now we can generate the points necessary for our curves!
nvalues = [32, 256, 512, 1024, 2048, 1024 * 5]
nor_losses = [fit_model(loss, n) for n in nvalues]
l1_losses = [fit_model(loss_l1, n) for n in nvalues]
l2_losses = [fit_model(loss_l2, n) for n in nvalues]
plt.plot(nvalues, nor_losses, label="No Regularization")
plt.plot(nvalues, l1_losses, label="L1 Regularization")
plt.plot(nvalues, l2_losses, label="L2 Regularization")
plt.legend()
plt.xlabel("Training Data Amount")
plt.ylabel("Test Loss")
plt.gca().set_yscale("log")
plt.gca().set_xscale("log")
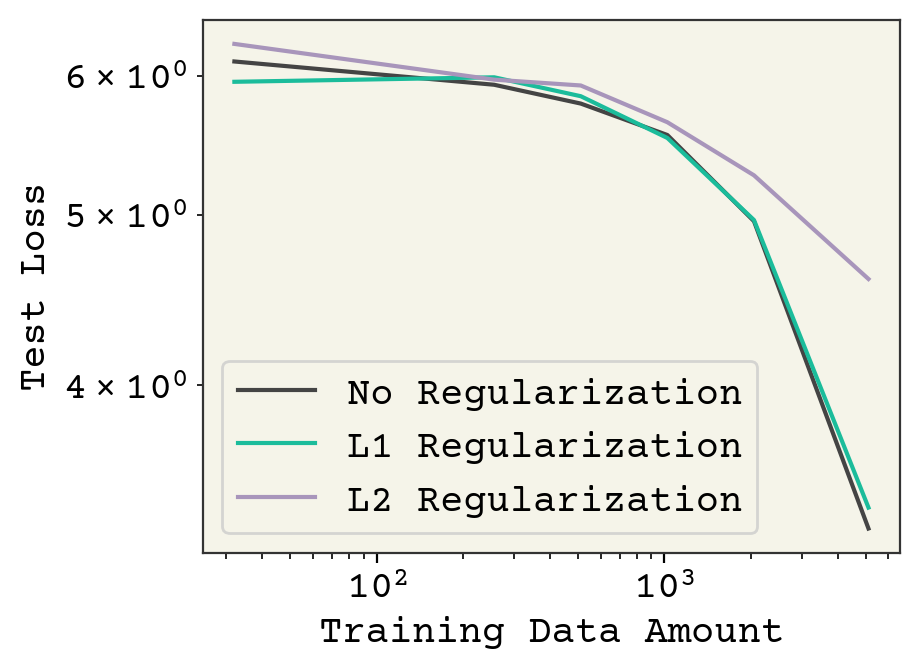
Finally, we see our training curves showing the different approaches. Regularization has some effect on final loss on the test data. It is hard to say if L1 and L2 are simply worse, or if I need to tune the regularization strength more. Nevertheless, this plot shows you how we typically evaluated kernel learning methods.
5.8. Exercises#
Compute the analytical gradient for the dual form regression equation and use it to describe why the kernel function does not need to be differentiable.
Is it faster or slower to do training with kernel learning? Explain
Is it faster or slower to do inference with kernel learning? Explain
How can we modify Equation 4.2 to do classification?
Do the weight values give relative importance of training examples regardless of kernel?
Create a training curve from the above example showing 5 different L1 regularization strengths. Why might regularization not matter here?
5.9. Chapter Summary#
In this section we introduced kernel learning, which is a method to transform features into distance between samples.
A kernel function takes two arguments and outputs a scalar. A kernel function must have three properties: positive, symmetric, and point-separating.
The distance function (inner product) is a kernel function.
Kernel functions do not need to be differentiable.
Kernel learning is appropriate when you would like to use features that can only be specified as a binary kernel function.
The number of trainable parameters in a kernel model is proportional to number of training points, not dimension of features.
5.10. Cited References#
Murat Cihan Sorkun, Abhishek Khetan, and Süleyman Er. AqSolDB, a curated reference set of aqueous solubility and 2D descriptors for a diverse set of compounds. Sci. Data, 6(1):143, 2019. doi:10.1038/s41597-019-0151-1.
Christoph Scherer, René Scheid, Denis Andrienko, and Tristan Bereau. Kernel-based machine learning for efficient simulations of molecular liquids. Journal of Chemical Theory and Computation, 16(5):3194–3204, 2020.
Matthias Rupp, Alexandre Tkatchenko, Klaus-Robert Müller, and O Anatole Von Lilienfeld. Fast and accurate modeling of molecular atomization energies with machine learning. Physical review letters, 108(5):058301, 2012.
Bojana Ranković, Ryan-Rhys Griffiths, Henry B. Moss, and Philippe Schwaller. Bayesian optimisation for additive screening and yield improvements in chemical reactions – beyond one-hot encodings. ChemRxiv, 2022. doi:10.26434/chemrxiv-2022-nll2j.
Ping Yang, E Adrian Henle, Xiaoli Z Fern, and Cory M Simon. Classifying the toxicity of pesticides to honey bees via support vector machines with random walk graph kernels. The Journal of Chemical Physics, 2022.