14. Variational Autoencoder#
A variational autoencoder (VAE) is a kind of generative deep learning model that is capable of unsupervised learning [KW13]. Unsupervised learning is the process of fitting models to unlabeled data. A generative model is a specific kind of unsupervised learning model that is capable of generating new data points that were not seen in training. Generative models can be viewed as a trained probability distribution over that data: \(\hat{\textrm{P}}(x)\). You can then draw samples from this distribution. It is generally too difficult to construct \(\hat{\textrm{P}}(x)\) directly, and so most generative models make some changes to the structure.
Audience & Objectives
This chapter builds on Standard Layers and Input Data & Equivariances. It also assumes a good knowledge of probability theory, including conditional probabilities. You can read my notes or any introductory probability text to get an overview. After completing this chapter, you should be able to
Understand the derivation for the loss function of a VAE
Construct an encoder/decoder pair in JAX and train it with the VAE loss function
Sample from the decoder
Rebalance VAE loss for reconstruction or disentangling
A VAE approaches this problem by introducing a dummy random variable \(z\), which we define to have a known distribution (e.g., normal). We can then rewrite \(\hat{\textrm{P}}(x)\) as:
using the definition of a marginal and conditional probability. Training \(\hat{\textrm{P}}\left(x | z \right)\) directly is not really possible either, but we can create a symmetric distribution \(\hat{\textrm{P}}\left(z | x \right)\) and train both simultaneously. This symmetric distribution only is created to help us train; our end goal is to find \(\hat{\textrm{P}}\left(x | z \right)\) so that we can obtain \(\hat{\textrm{P}}(x)\). VAEs were first introduced in [KW13].
A VAE is thus a set of two trained conditional probability distributions that operate on the data \(x\) and latent variables \(z\). The first conditional is \(p_\theta(x | z)\), where \(\theta\) indicates the trainable parameters that we will be fitting. \(p_\theta(x | z)\) is known as the “decoder” because it goes from the latent variable \(z\) to \(x\). The decoder analogy is because you can view \(z\) as a kind of encoded compression of \(x\). The other conditional is \(q_\phi(z | x)\) and is known as the encoder.
Remember we always know \(p(z)\) because we chose it to be a defined distribution — that is the key idea. We’re grounding our encoder/decoder by having them communicate through \(p(z)\), which we know. For the rest of this chapter we’ll take \(p(z)\) to be a standard normal distribution. \(p(z)\) can be other distributions though. It can even be trained using the techniques from the Normalizing Flows.
14.1. VAE Loss function#
To see how \(q_\phi(z | x)\) enables us to train, let’s construct our loss. The loss function should only take in a value \(x_i\) and trainable parameters. There are no labels. Our goal is to make our VAE model be able to generate \(x_i\), so the loss is the log likelihood that we saw \(x_i\): \(\log\left[\hat{\textrm{P}}(x_i)\right]\).
14.1.1. Derivation#
Note
The derivation below is a little unusual. Most derivations rely on Bayes’ theorem following a principle of evidence lower bound (ELBO). I thought I’d give a different derivation since you can readily find examples of the ELBO in many places.
Remember we do not have an expression for \(\hat{\textrm{P}}(x_i)\). We have \(p_\theta(x_i | z)\). To connect them we’ll use the following expression:
where we have rewritten the integral more compactly by using the definition of expectation. This expression requires integrating over the latent variable, which is not easy since as you can guess \(p_\theta(x | z)\) is a neural network and it’s not straightforward to integrate over the input (\(z\)) of a neural network. Instead, we can approximate this integral by sampling some \(z\)s from \(P(z)\)
You’ll find though that grabbing \(z\)’s from \(P(z)\) is not so efficient at approximating this integral, because you need the \(z\)’s to be likely to have led to the observed \(x_i\). The integral is dominated by the \(p_\theta(x_i | z_j)\) terms. This is where we use \(q(z | x)\): it can provide efficient guesses for \(z_j\). To approximate \(\log \textrm{E}_z\left[p_\theta(x_i | z)\right]\) with samples from \(q(z | x_i)\), we need to account for the fact that sampling from \(q(z | x_i)\) is not identical to sampling from \(P(z)\) by adding their ratio to the expression (importance sampling).
The ratio of \(P(z) / q_\phi(z | x)\) enables our numerical approximation of the expectation. For notational purposes though I’ll go back to the exact expression, with the understanding that when we go to implementation we’ll use the numerical approximation:
Notice how the expectation now is wrt \(z \sim q_\phi(z | x_i)\) since we have that importance sampling ratio in the expression.
Now if the log was on the inside of our expectation, we could simplify this. We can actually swap the order of expectation and the log using Jensen’s Inequality for the concave log function. The consequence is that our loss is no longer an exact estimate of the log likelihood, but a lower bound.
We’ll use that and can now separate into two terms by properties of the log
Remember we always planned to re-introduce numerically approximate the expectation. However, the right-hand side does not involve \(p_\theta(x | z)\), so we do not need to integrate over a neural network input. We just need to integrate over the output of \(q_\phi(z | x)\) and \(P(z)\), which is a standard normal distribution. We’ll see later on that we can make the output of \(q_\phi(z | x)\) specifically be a normal distribution to make sure we can easily compute the integral. Finally, we can use an identity that relates the Kullback–Leibler divergence (KL divergence) (a binary functional of two probabilities) to the right-hand side term:
arriving at our final result:
14.1.2. Log-Likelihood Approximation#
The left term is called the reconstruction loss and assess how close we come after going from \(x \rightarrow z \rightarrow x\) in expectation. The right-hand term is the KL-divergence and measures how close our encoder is to our defined \(P(z)\) (normal distribution). The right-hand term involves an integral that can be computed analytically and no sampling is required to estimate it. Remember, in the derivation the KL-divergence term appeared as a correction term to account for the fact that our loss doesn’t use \(P(z)\) directly, but instead uses the encoder \(q_\phi(z | x_i)\) which generates \(z\)’s from our training data point \(x_i\). The last step is that we want to minimize our loss, so we need to add a minus sign.
Note
The log-likelihood equation we’ve derived for VAE training is also sometimes called the evidence lower bound (ELBO). ELBO is a general equation used in Bayesian modeling, which usually has nothing to do with VAEs.
Remember that in practice, we will approximate the expectation in the reconstruction loss by sampling \(z\)’s from the decoder \(q_\phi(z | x)\). We’ll only use a single sample.
14.2. Running This Notebook#
Click the above to launch this page as an interactive Google Colab. See details below on installing packages.
Tip
To install packages, execute this code in a new cell.
!pip install dmol-book
If you find install problems, you can get the latest working versions of packages used in this book here
14.3. VAE for Discrete Data#
Our first example will be to generate new example classes from a distribution of possible classes. An application for this might be to sample conditions of an experiment. Our features \(x\) are one-hot vectors indicating class and our goal is to learn the distribution \(P(x)\) so that we can sample new \(x\)’s. Learning the latent space can also provide a way to embed your features into low dimensional continuous vectors, allowing you to do things like optimization because you’ve moved from discrete classes to continuous vectors. That is an extra benefit, our loss and training goal are to create a new \(P(x)\).
Let’s think for a moment about our encoder and decoder. \(q_\phi(z | x)\), the encoder, should give out a probability distribution for vectors of real numbers \(z\) and take an input of a one-hot vector \(x\). This sounds difficult; we’ve never seen a neural network output a probability distribution over real number vectors. We can simplify though. We defined \(P(z)\) to be normally distributed, let’s assume that the form of \(q_\phi(z | x)\) should be normal. Then our neural network could output the parameters to a normal distribution (mean/variance) for \(z\), rather than trying to output a probability at every possible \(z\) value. It’s up to you if you want to have \(q_\phi(z | x)\) output a D-dimensional Gaussian distribution with a covariance matrix or just output D independent normal distributions. Having \(q_\phi(z | x)\) output a normal distribution also allows us to analytically simplify the expectation/integral in the KL-divergence term.
The decoder \(p_\theta(x | z)\) should output a probability distribution over classes given a real vector \(z\). We can use the same form we used for classification: softmax activation. Just remember that we’re not trying to output a specific \(x\), just a probability distribution of \(x\)’s.
Choices we have to make are the hyperparameters of the encoder and decoder and the size of \(z\). It makes sense to have the encoder and decoder share as many hyperparameters as possible, since they’re somewhat symmetric. Just remember that the encoder in our example is outputting a mean and variance, which means using regression, and the decoder is outputting a normalized probability vector, which means using softmax. Let’s get started!
14.3.1. The Data#
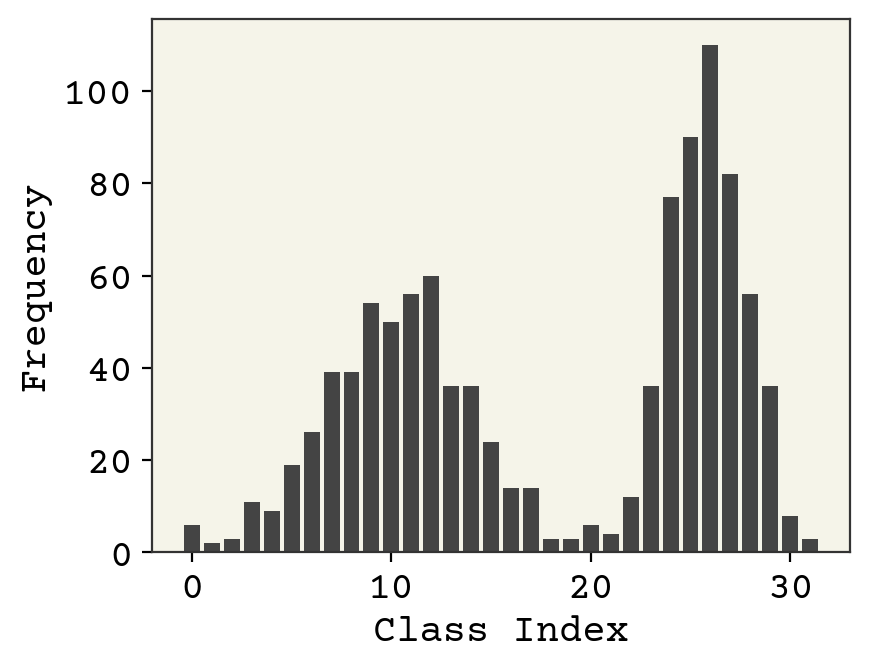
The data is 1024 points \(\vec{x}_i\) where each \(\vec{x}_i\) is a 32 dimensional one-hot vector indicating class. We won’t define the classes – the data is synthetic. Since a VAE is unsupervised learning, there are no labels. Let’s start by examining the data. We’ll sum the occurrences of each class to see what the distribution of classes looks like. The hidden cells show how the data was generated
import numpy as np
import matplotlib.pyplot as plt
import urllib
import seaborn as sns
import dmol
plt.bar(np.arange(nclasses), height=np.sum(class_data, axis=0))
plt.xlabel("Class Index")
plt.ylabel("Frequency")
plt.show()
14.3.2. The encoder#
Our encoder will be a basic two hidden layer network. We will output a \(D\times2\) matrix, where the first column is means and the second is standard deviations for independent normal distributions that make up our guess for \(q(z | x)\). Outputting a mean is simple, just use no activation. Outputting a standard deviation is unusual because they should be on \((0, \infty)\). jax.nn.softplus can accomplish this.
import jax.numpy as jnp
from jax.example_libraries import optimizers
import jax
import functools
def random_vec(size):
return np.random.normal(size=size, scale=1)
latent_dim = 1
hidden_dim = 16
input_dim = nclasses
def encoder(x, theta):
"""The encoder takes as input x and gives out probability of z,
expressed as normal distribution parameters. Assuming each z dim is independent,
output |z| x 2 matrix"""
w1, w2, w3, b1, b2, b3 = theta
hx = jax.nn.relu(w1 @ x + b1)
hx = jax.nn.relu(w2 @ hx + b2)
out = w3 @ hx + b3
# slice out stddeviation and make it positive
reshaped = out.reshape((-1, 2))
# we slice with ':' to keep rank same
std = jax.nn.softplus(reshaped[:, 1:])
mu = reshaped[:, 0:1]
return jnp.concatenate((mu, std), axis=1)
def init_theta(input_dim, hidden_units, latent_dim):
"""Create inital theta parameters"""
w1 = random_vec(size=(hidden_units, input_dim))
b1 = np.zeros(hidden_units)
w2 = random_vec(size=(hidden_units, hidden_units))
b2 = np.zeros(hidden_units)
# need to params per dim (mean, std)
w3 = random_vec(size=(latent_dim * 2, hidden_units))
b3 = np.zeros(latent_dim * 2)
return [w1, w2, w3, b1, b2, b3]
# test them
theta = init_theta(input_dim, hidden_dim, latent_dim)
encoder(class_data[0], theta)
Array([[5.9566455 , 0.14336935]], dtype=float32)
The decoder should output a vector of probabilities for \(\vec{x}\). This can be achieved by just adding a softmax to the output. The rest is nearly identical to the encoder.
def decoder(z, phi):
"""decoder takes as input the latant variable z and gives out probability of x.
Decoder outputes a real number, then we use softmax activation to get probability across
possible values of x.
"""
w1, w2, w3, b1, b2, b3 = phi
hz = jax.nn.relu(w1 @ z + b1)
hz = jax.nn.relu(w2 @ hz + b2)
out = jax.nn.softmax(w3 @ hz + b3)
return out
def init_phi(input_dim, hidden_units, latent_dim):
"""Create inital phi parameters"""
w1 = random_vec(size=(hidden_units, latent_dim))
b1 = np.zeros(hidden_units)
w2 = random_vec(size=(hidden_units, hidden_units))
b2 = np.zeros(hidden_units)
w3 = random_vec(size=(input_dim, hidden_units))
b3 = np.zeros(input_dim)
return [w1, w2, w3, b1, b2, b3]
# test it out
phi = init_phi(input_dim, hidden_dim, latent_dim)
decoder(np.array([1.2] * latent_dim), phi)
Array([5.1830584e-06, 8.8399119e-09, 8.5372856e-05, 7.7054265e-09,
3.6683598e-06, 1.2794550e-04, 9.6987858e-09, 2.3822258e-06,
3.8151384e-06, 7.9184854e-09, 3.7569658e-09, 2.6414519e-08,
1.4017490e-08, 2.4130357e-05, 1.8144948e-06, 5.6384699e-11,
8.3609098e-01, 1.0534998e-09, 6.9088594e-07, 4.0899907e-04,
3.1356729e-04, 7.6400262e-05, 1.2817173e-09, 1.3985705e-07,
1.6225461e-02, 6.3542196e-08, 4.7430876e-06, 6.7662097e-07,
4.1029431e-05, 2.0750994e-08, 1.4658265e-01, 2.6876736e-08], dtype=float32)
14.4. Training#
We use ELBO equation for training:
where \(P(z)\) is the standard normal distribution and we approximate expectations using a single sample from the encoder. We need to expand the KL-divergence term to implement. Both \(P(z)\) and \(q_\theta(z | x)\) are normal. You can look-up the KL-divergence between two normal distributions:
we can simplify because \(P(z)\) is standard normal (\(\sigma = 1, \mu = 0\))
where \(\mu_i, \sigma_i\) are the output from \(q_\phi(z | x_i)\)
@jax.jit
def loss(x, theta, phi, rng_key):
"""VAE Loss"""
# reconstruction loss
sampled_z_params = encoder(x, theta)
# reparameterization trick
# we use standard normal sample and multiply by parameters
# to ensure derivatives correctly propogate to encoder
sampled_z = (
jax.random.normal(rng_key, shape=(latent_dim,)) * sampled_z_params[:, 1]
+ sampled_z_params[:, 0]
)
# log of prob
rloss = -jnp.log(decoder(sampled_z, phi) @ x.T + 1e-8)
# LK loss
klloss = (
-0.5
- jnp.log(sampled_z_params[:, 1])
+ 0.5 * sampled_z_params[:, 0] ** 2
+ 0.5 * sampled_z_params[:, 1] ** 2
)
# combined
return jnp.array([rloss, jnp.mean(klloss)])
# test it out
loss(class_data[0], theta, phi, jax.random.PRNGKey(0))
Array([18.420681, 19.19342 ], dtype=float32)
Our loss works! Now we need to make it batched so we can train in batches. Luckily this is easy with vmap.
batched_loss = jax.vmap(loss, in_axes=(0, None, None, None), out_axes=0)
batched_decoder = jax.vmap(decoder, in_axes=(0, None), out_axes=0)
batched_encoder = jax.vmap(encoder, in_axes=(0, None), out_axes=0)
# test batched loss
batched_loss(class_data[:4], theta, phi, jax.random.PRNGKey(0))
Array([[18.420681, 19.193424],
[18.420681, 88.56056 ],
[18.420681, 55.28206 ],
[18.420681, 19.193424]], dtype=float32)
We’ll make our gradient take the average over the batch
grad = jax.grad(
lambda x, theta, phi, rng_key: jnp.mean(batched_loss(x, theta, phi, rng_key)),
(1, 2),
)
fast_grad = jax.jit(grad)
fast_loss = jax.jit(batched_loss)
Alright, great! An important detail we’ve skipped so far is that when using jax to generate random numbers, we must step our random number generator forward. You can do that using jax.random.split. Otherwise, you’ll get the same random numbers at each draw.
We’re going to use a jax optimizer here. This is to simplify parameter updates. We have a lot of parameters and they are nested, which will be complex for treating with python for loops.
batch_size = 32
epochs = 16
key = jax.random.PRNGKey(0)
opt_init, opt_update, get_params = optimizers.adam(step_size=1e-1)
theta0 = init_theta(input_dim, hidden_dim, latent_dim)
phi0 = init_phi(input_dim, hidden_dim, latent_dim)
opt_state = opt_init((theta0, phi0))
losses = []
for e in range(epochs):
for bi, i in enumerate(range(0, len(data), batch_size)):
# make a batch into shape B x 1
batch = class_data[i : (i + batch_size)]
# udpate random number key
key, subkey = jax.random.split(key)
# get current parameter values from optimizer
theta, phi = get_params(opt_state)
last_state = opt_state
# compute gradient and update
grad = fast_grad(batch, theta, phi, key)
opt_state = opt_update(bi, grad, opt_state)
lvalue = jnp.mean(fast_loss(batch, theta, phi, subkey), axis=0)
losses.append(lvalue)
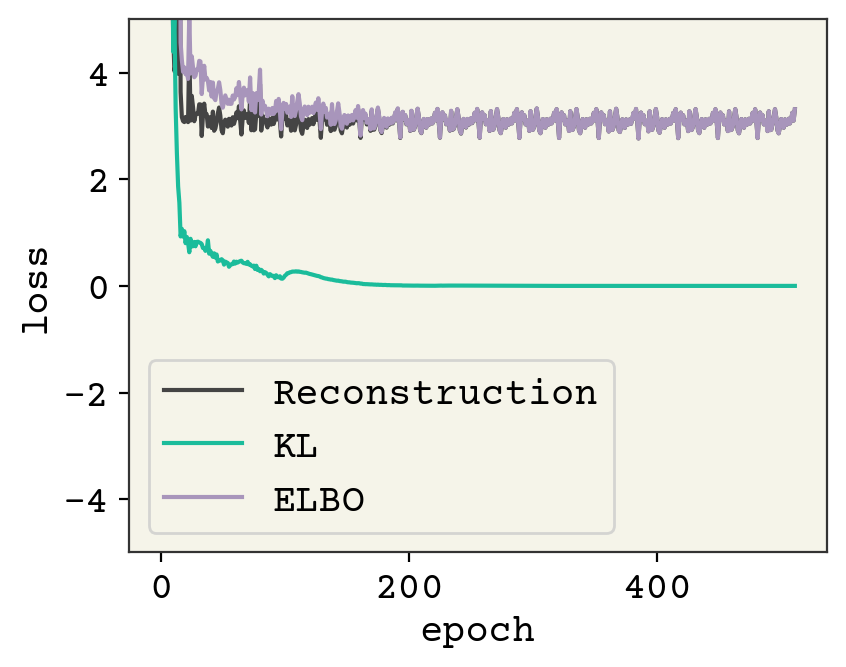
plt.plot([l[0] for l in losses], label="Reconstruction")
plt.plot([l[1] for l in losses], label="KL")
plt.plot([l[1] + l[0] for l in losses], label="ELBO")
plt.legend()
plt.ylim(-5, 5)
plt.xlabel("epoch")
plt.ylabel("loss")
plt.show()
14.4.1. Evaluating the VAE#
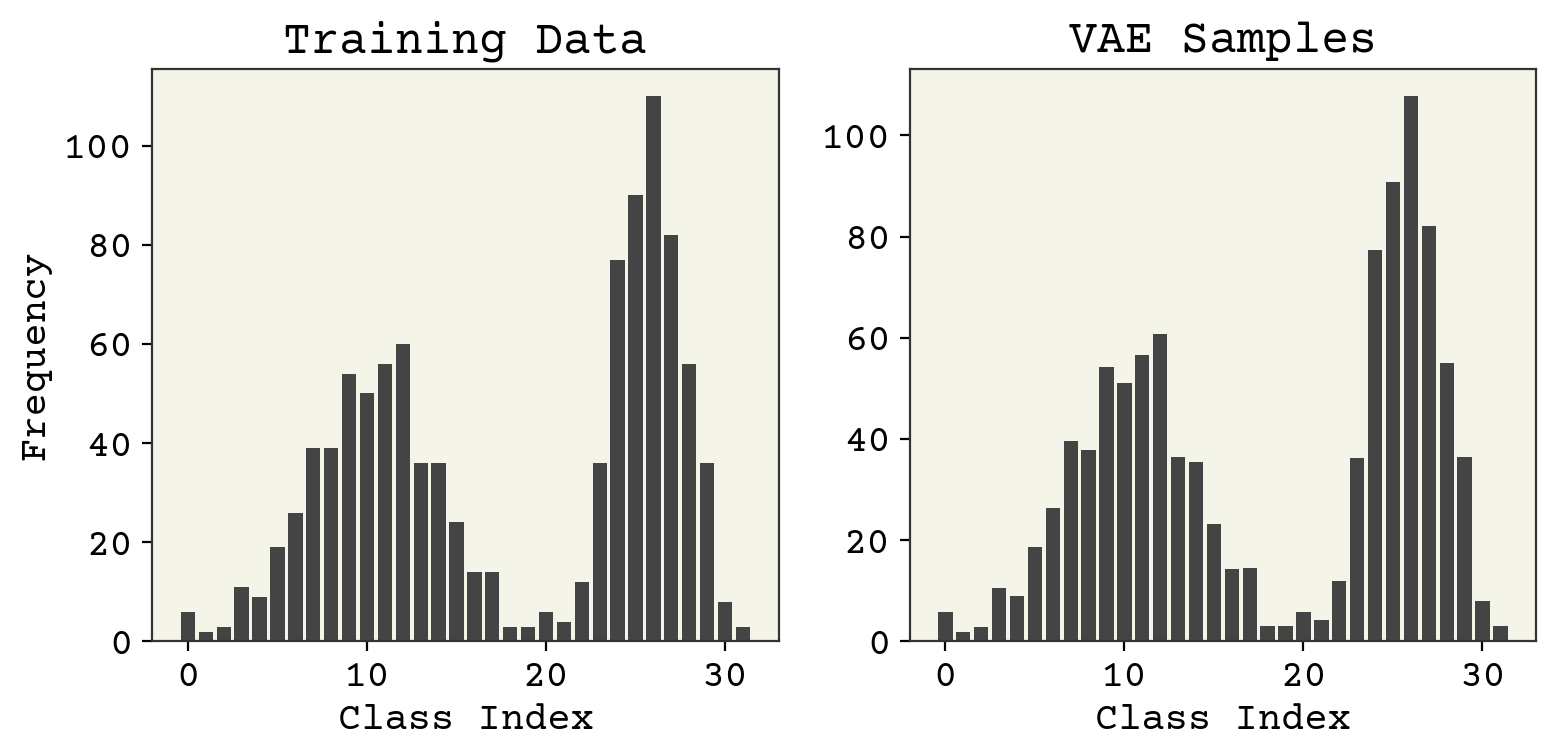
Remember our goal with the VAE is to reproduce \(P(x)\). We can sample from our VAE using the chosen \(P(z)\) and our decoder. Let’s compare that distribution with our training distribution.
zs = np.random.normal(size=(1024, 1))
sampled_x = batched_decoder(zs, phi)
fig, axs = plt.subplots(ncols=2, figsize=(8, 4))
axs[0].set_title("Training Data")
axs[0].bar(np.arange(nbins), height=np.sum(class_data, axis=0))
axs[0].set_xlabel("Class Index")
axs[0].set_ylabel("Frequency")
axs[1].set_title("VAE Samples")
axs[1].bar(np.arange(nbins), height=np.sum(sampled_x, axis=0))
axs[1].set_xlabel("Class Index")
plt.tight_layout()
plt.show()
It appears we have succeeded! There were two more goals of the VAE model: making the encoder give output similar to \(P(z)\) and be able to reconstruct. These goals are often opposed and they represent the two terms in the loss: reconstruction and KL-divergence. Let’s examine the KL-divergence term, which causes the encoder to give output similar to a standard normal. We’ll sample from our training data in histogram look at the resulting average mean and std dev.
d = batched_encoder(class_data, theta)
print("Average mu = ", np.mean(d[..., 0]), "Average std dev = ", np.mean(d[..., 1]))
Average mu = 0.00030671438 Average std dev = 0.99916613
Wow! Very close to a standard normal. So our model satisfied the match between the decoder and the \(P(z)\). The last thing to check is reconstruction. These are distributions, so I’ll only look at the maximum \(z\) value to do the reconstruction.
plt.plot(decoder(encoder(class_data[2], theta)[0:1, 0], phi), label="P(x)")
plt.axvline(np.argmax(class_data[2]), color="C1", label="x")
plt.legend()
plt.show()
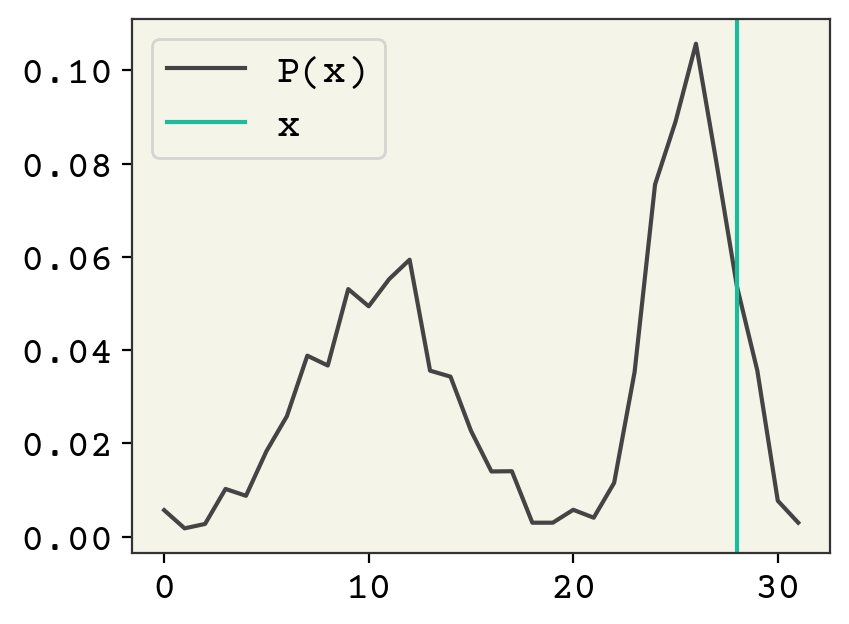
The reconstruction is not great, it puts a lot of probability mass on other points. In fact, the reconstruction seems to not use the encoder’s information at all – it looks like \(P(x)\). The reason for this is that our KL-divergence term dominates. It has a very good fit.
14.5. Re-balancing VAE Reconstruction and KL-Divergence#
Often we desire more reconstruction at the cost of making the latent space less normal. This can be done by adding a term that adjusts the balance between the reconstruction loss and the KL-divergence. You would choose to do this if you want to use the latent space for something and are not just interested in creating a model \(\hat{P}(x)\). Here is the modified ELBO equation for training:
where \(\beta > 1\) emphasizes the encoder distribution matching chosen latent distribution (standard normal) and \(\beta < 1\) emphasizes reconstruction accuracy.
def modified_loss(x, theta, phi, rng_key, beta):
"""This loss allows you to vary which term is more important
with beta. Beta = 0 - all reconstruction, beta = 1 - ELBO"""
bl = batched_loss(x, theta, phi, rng_key)
l = bl @ jnp.array([1.0, beta])
return jnp.mean(l)
new_grad = jax.grad(modified_loss, (1, 2))
fast_grad = jax.jit(new_grad)
# note we used a lower step size for this loss
# and more epochs
opt_init, opt_update, get_params = optimizers.adam(step_size=5e-2)
epochs = 32
theta0 = init_theta(input_dim, hidden_dim, latent_dim)
phi0 = init_phi(input_dim, hidden_dim, latent_dim)
opt_state = opt_init((theta0, phi0))
beta = 0.2
losses = []
for e in range(epochs):
for bi, i in enumerate(range(0, len(data), batch_size)):
# make a batch into shape B x 1
batch = class_data[i : (i + batch_size)]
# udpate random number key
key, subkey = jax.random.split(key)
# get current parameter values from optimizer
theta, phi = get_params(opt_state)
last_state = opt_state
# compute gradient and update
grad = fast_grad(batch, theta, phi, key, beta)
opt_state = opt_update(bi, grad, opt_state)
lvalue = jnp.mean(fast_loss(batch, theta, phi, subkey), axis=0)
losses.append(lvalue)
plt.plot([l[0] for l in losses], label="Reconstruction")
plt.plot([l[1] for l in losses], label="KL")
plt.plot([l[1] + l[0] for l in losses], label="ELBO")
plt.legend()
plt.ylim(-5, 5)
plt.xlabel("epoch")
plt.ylabel("loss")
plt.show()
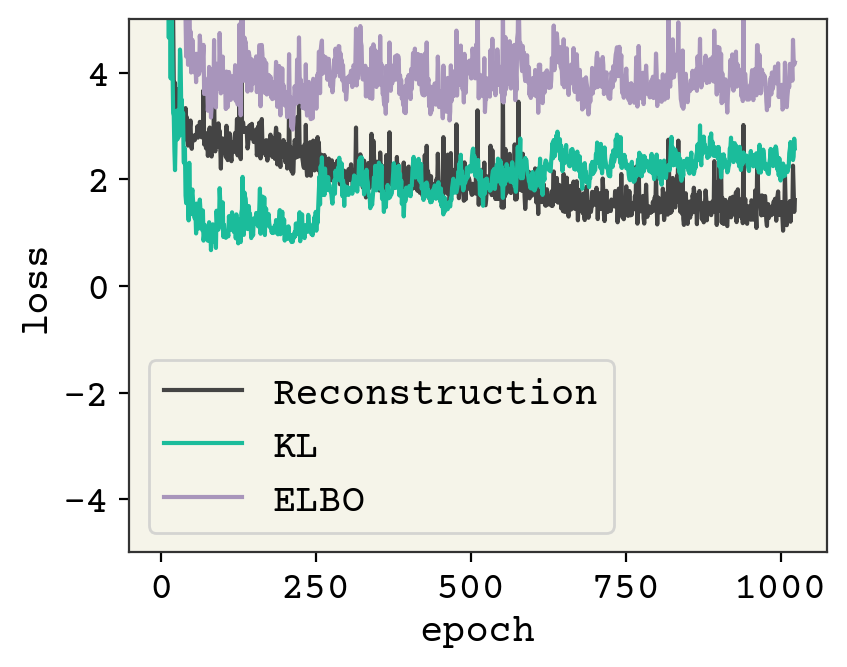
You can see the error is higher, but let’s see how it did at our three metrics.
zs = np.random.normal(size=(1024, 1))
sampled_x = batched_decoder(zs, phi)
fig, axs = plt.subplots(ncols=2, figsize=(8, 4))
axs[0].set_title("Training Data")
axs[0].bar(np.arange(nbins), height=np.sum(class_data, axis=0))
axs[0].set_xlabel("Class Index")
axs[0].set_ylabel("Frequency")
axs[1].set_title("VAE Samples")
axs[1].bar(np.arange(nbins), height=np.sum(sampled_x, axis=0))
axs[1].set_xlabel("Class Index")
plt.tight_layout()
plt.show()
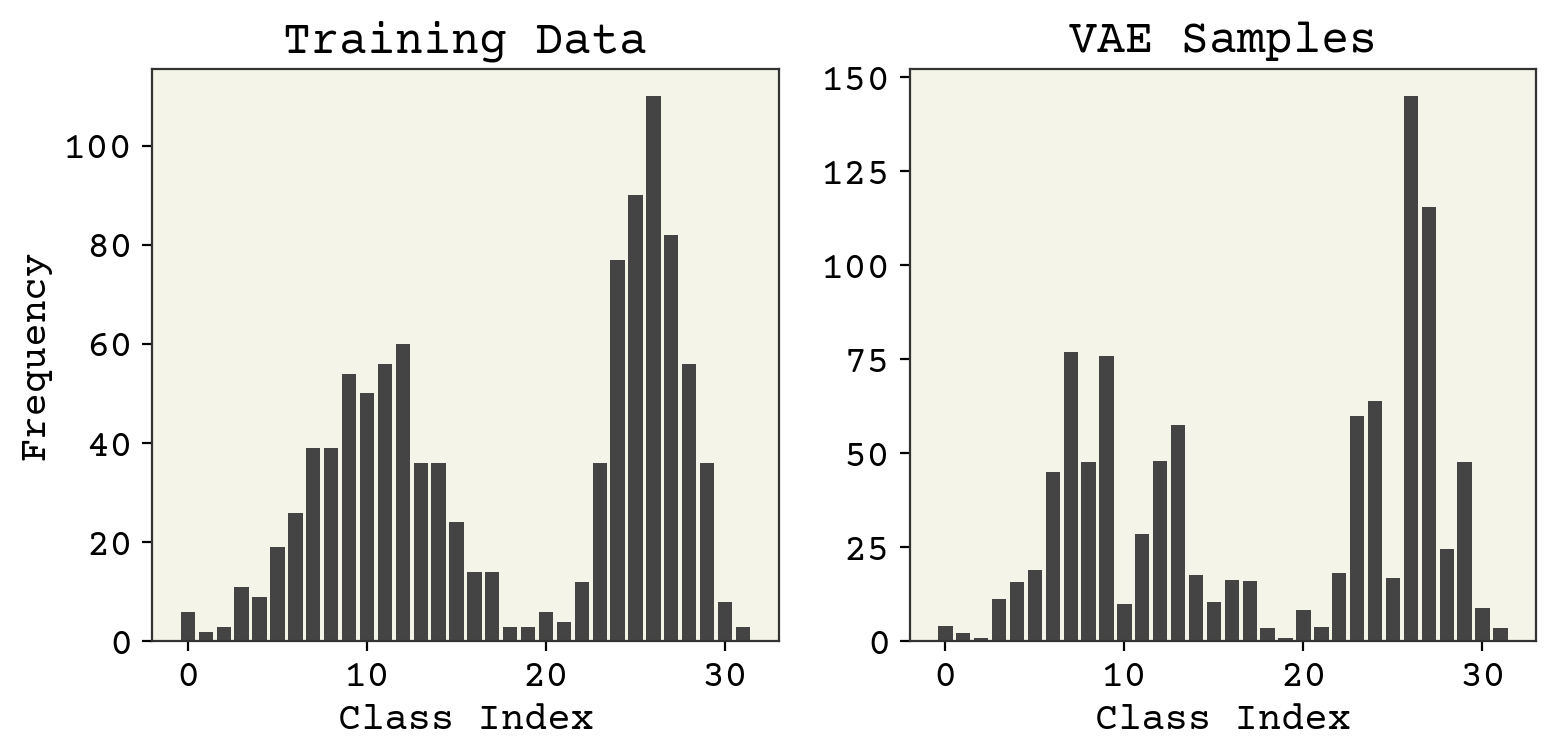
A little bit worse on \(P(x)\), but overall not bad. What about our goal, the reconstruction?
plt.plot(decoder(encoder(class_data[4], theta)[0:1, 0], phi), label="P(x)")
plt.axvline(np.argmax(class_data[4]), color="C1", label="x")
plt.legend()
plt.show()
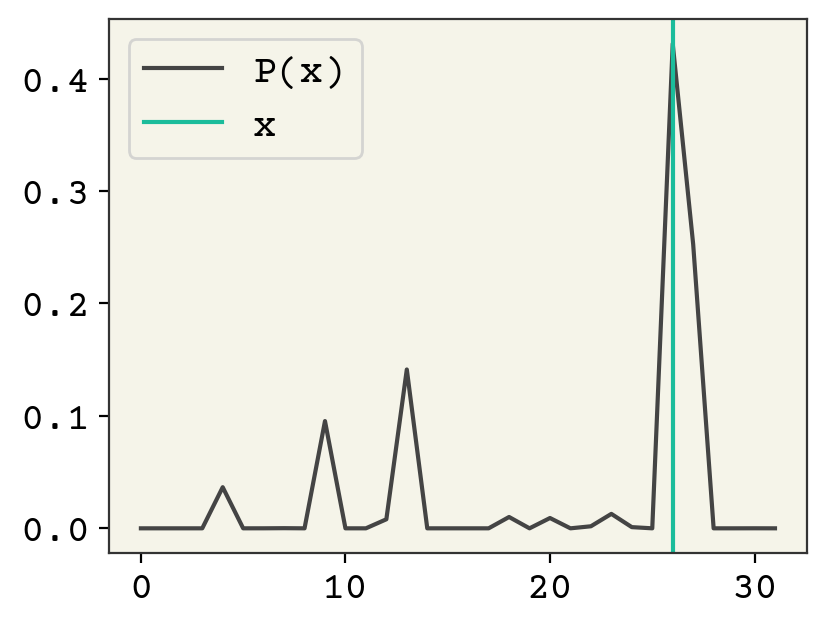
What about our encoder’s agreement with a standard normal?
d = batched_encoder(class_data, theta)
print("Average mu = ", np.mean(d[..., 0]), "Average std dev = ", np.mean(d[..., 1]))
Average mu = -0.02217746 Average std dev = 0.11638635
The standard deviation is much smaller! So we squeezed our latent space a little at the cost of better reconstruction.
14.5.1. Disentangling \(\beta\)-VAE#
You can adjust \(\beta\) the opposite direction, to value matching the prior Gaussian distribution more strongly. This can better condition the encoder so that each of the latent dimensions are truly independent. This can be important if you want to disengatngle your input features to arrive at an orthogonal projection. This of course comes at the loss of reconstruction accuracy, but can be more important if you’re interested in the latent space rather than generating new samples [MRST19].
14.6. Regression VAE#
We’ll now work with continuous features \(x\). We need to make a few key changes. The encoder will remain the same, but the decoder now must output a \(p_\theta(x | z)\) that gives a probability to all possible \(x\) values. Above, we only had a finite number of classes but now any \(x\) is possible. As we did for the encoder, we’ll assume that \(p_\theta(x | z)\) should be normal and we’ll output the parameters of the normal distribution from our network. This requires an update to the reconstruction loss to be a log of a normal, but otherwise things will be identical.
One of the mistakes I always make is that the log-likelihood for a normal distribution with a single observation cannot have unknown standard deviation. Our new normal distribution parameters for the decoder will have a single observation for a single \(x\) in training. If you make the standard deviation trainable, it will just pick infinity as the standard deviation since that will for sure capture the point and you only have one point. Thus, I’ll make the decoder standard deviation be a hyperparameter fixed at 0.1. We don’t see this issue with the encoder, which also outputs a normal distribution, because we training the encoder with the KL-divergence term and not likelihood of observations (reconstruction loss).
latent_dim = 1
hidden_dim = 16
input_dim = 1
# make encoder parameters
theta = init_theta(input_dim, hidden_dim, latent_dim)
# test it
encoder(data[0:1], theta)
Array([[-0.74173325, 0.19359773]], dtype=float32)
def decoder(z, phi):
"""decoder takes as input the latant variable z and gives out probability of x.
Decoder outputes parameters for a normal distribution
"""
w1, w2, w3, b1, b2, b3 = phi
hz = jax.nn.relu(w1 @ z + b1)
hz = jax.nn.relu(w2 @ hz + b2)
out = w3 @ hz + b3
# slice out stddeviation and make it positive
reshaped = out.reshape((-1, 2))
# we slice with ':' to keep rank same
# std = jax.nn.softplus(reshaped[:,1:])
std = jnp.ones_like(reshaped[:, 1:]) * 0.1
mu = reshaped[:, 0:1]
return jnp.concatenate((mu, std), axis=1)
def init_phi(input_dim, hidden_units, latent_dim):
"""Create inital phi parameters"""
w1 = random_vec(size=(hidden_units, latent_dim))
b1 = np.zeros(hidden_units)
w2 = random_vec(size=(hidden_units, hidden_units))
b2 = np.zeros(hidden_units)
w3 = random_vec(size=(input_dim * 2, hidden_units))
b3 = np.zeros(input_dim * 2)
return [w1, w2, w3, b1, b2, b3]
# test it out
phi = init_phi(input_dim, hidden_dim, latent_dim)
decoder(np.array([1.2] * latent_dim), phi)
Array([[-3.2090921, 0.1 ]], dtype=float32)
@jax.jit
def loss(x, theta, phi, rng_key):
"""VAE Loss"""
# reconstruction loss
sampled_z_params = encoder(x, theta)
# reparameterization trick
# we use standard normal sample and multiply by parameters
# to ensure derivatives correctly propogate to encoder
sampled_z = (
jax.random.normal(rng_key, shape=(latent_dim,)) * sampled_z_params[:, 1]
+ sampled_z_params[:, 0]
)
# log of normal dist
out_params = decoder(sampled_z, phi)
rloss = (
-jnp.log(jnp.sqrt(2 * np.pi) * out_params[:, 1] + 1e-10)
+ (x - out_params[:, 0]) ** 2 / out_params[:, 1] ** 2 / 2
)
klloss = (
-0.5
- jnp.log(sampled_z_params[:, 1])
+ 0.5 * sampled_z_params[:, 0] ** 2
+ 0.5 * sampled_z_params[:, 1] ** 2
)
# combined
return jnp.array([jnp.mean(rloss), jnp.mean(klloss)])
# test it out
loss(data[0:1], theta, phi, jax.random.PRNGKey(0))
# update compiled functions
batched_loss = jax.vmap(loss, in_axes=(0, None, None, None), out_axes=0)
batched_decoder = jax.vmap(decoder, in_axes=(0, None), out_axes=0)
batched_encoder = jax.vmap(encoder, in_axes=(0, None), out_axes=0)
grad = jax.grad(
lambda x, theta, phi, rng_key: jnp.mean(batched_loss(x, theta, phi, rng_key)),
(1, 2),
)
fast_grad = jax.jit(grad)
fast_loss = jax.jit(batched_loss)
batch_size = 32
epochs = 64
key = jax.random.PRNGKey(0)
opt_init, opt_update, get_params = optimizers.adam(step_size=1e-2)
theta0 = init_theta(input_dim, hidden_dim, latent_dim)
phi0 = init_phi(input_dim, hidden_dim, latent_dim)
opt_state = opt_init((theta0, phi0))
losses = []
for e in range(epochs):
for bi, i in enumerate(range(0, len(data), batch_size)):
# make a batch into shape B x 1
batch = data[i : (i + batch_size)].reshape(-1, 1)
# udpate random number key
key, subkey = jax.random.split(key)
# get current parameter values from optimizer
theta, phi = get_params(opt_state)
last_state = opt_state
# compute gradient and update
grad = fast_grad(batch, theta, phi, key)
opt_state = opt_update(bi, grad, opt_state)
lvalue = jnp.mean(fast_loss(batch, theta, phi, subkey), axis=0)
losses.append(lvalue)
plt.plot([l[0] for l in losses], label="Reconstruction")
plt.plot([l[1] for l in losses], label="KL")
plt.plot([l[1] + l[0] for l in losses], label="ELBO")
plt.legend()
plt.ylim(-5, 20)
plt.xlabel("epoch")
plt.ylabel("loss")
plt.show()
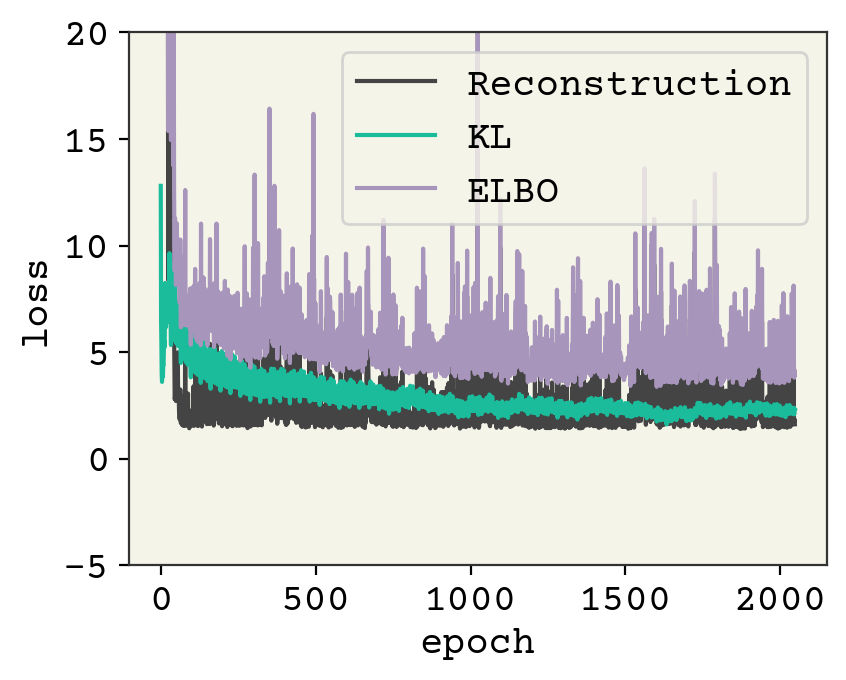
This model still has training to be done, but hopefully you get the idea for working with continuous numbers! We can examine the final result below. Note that I must sample from the output parameters to compare with the real training data.
bins = 64
zs = np.random.normal(size=(1024, 1))
sampled_x_params = batched_decoder(zs, phi)
fig, axs = plt.subplots(ncols=2, figsize=(8, 4))
axs[0].set_title("Training Data")
_, bins, _ = axs[0].hist(data, bins=bins)
axs[0].set_xlabel("x")
axs[0].set_ylabel("Frequency")
axs[1].set_title("VAE Samples")
# Now we have to sample from output paramters!!
samples = []
for s in sampled_x_params:
samples.append(np.random.normal(scale=s[:, 1], loc=s[:, 0], size=(8)))
samples = np.array(samples).flatten()
# make them use same bins
axs[1].hist(samples, bins=bins)
axs[1].set_xlabel("x")
plt.tight_layout()
plt.show()
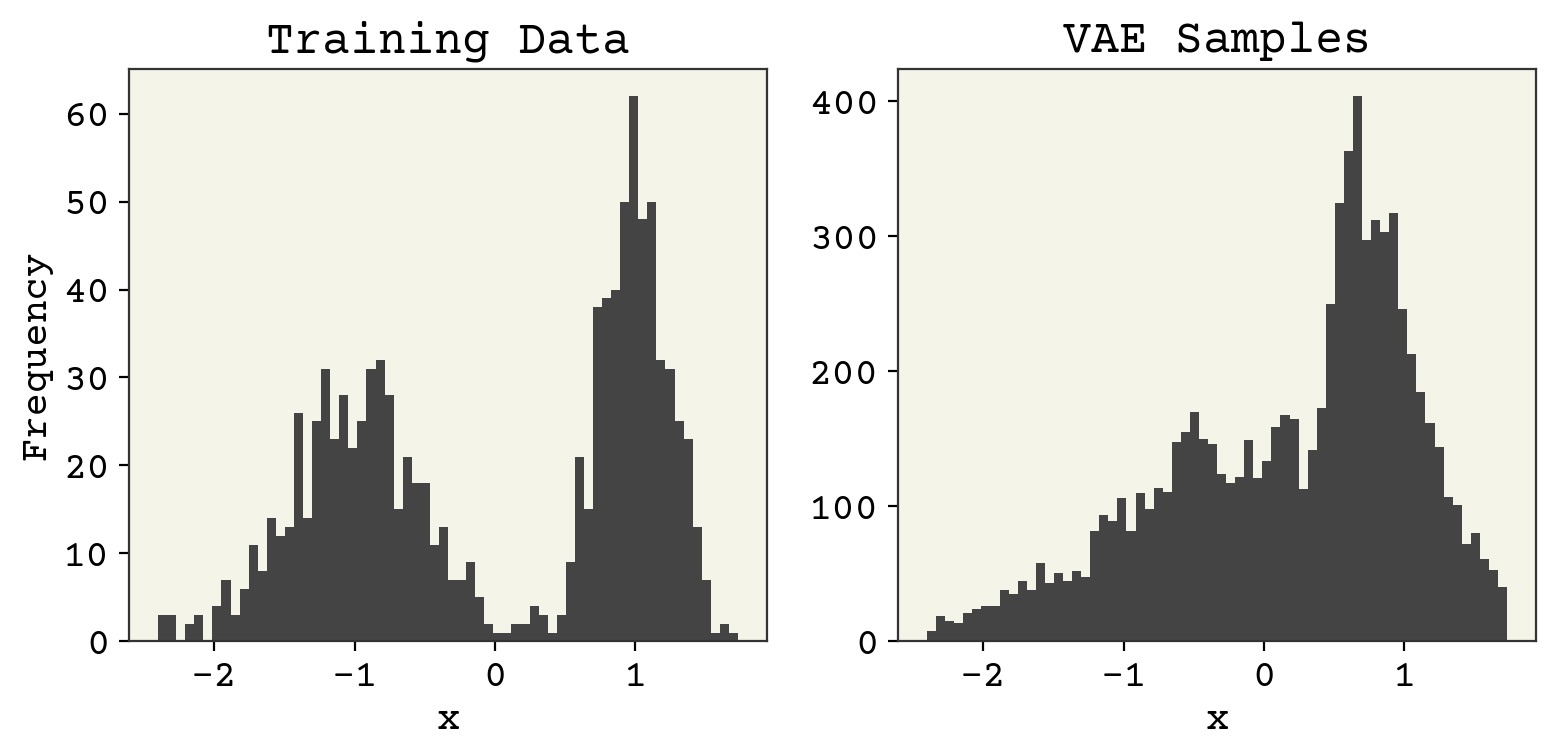
The distribution is alright, not great. Comparing reconstruction is a little different because we only compare the mean of the predicted \(P(x)\). We’ll plot our predicted \(\mu\) from the decoder against the real \(x\) values.
mus = batched_decoder(batched_encoder(data.reshape(-1, 1), theta)[:, :, 0], phi)[
:, 0, 0
]
plt.plot(data, mus, ".")
plt.plot(data, data, "-", zorder=-1, color="gray")
plt.xlabel("x")
plt.ylabel("$\mu$")
plt.show()
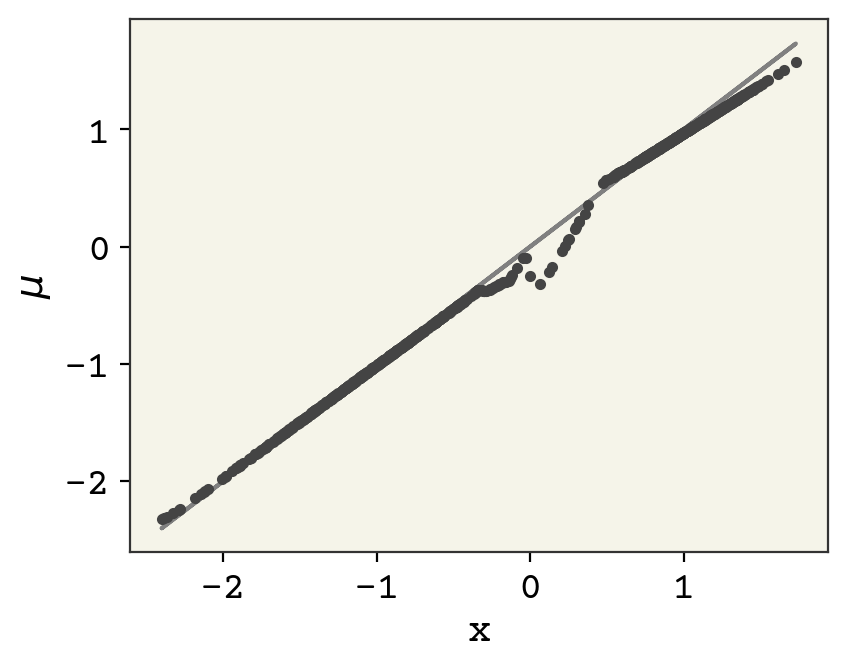
The reconstruction is actually quite good! There is some odd behavior near the top, but otherwise quite reasonable. Finally check how well we did with getting our latent space to be standard normal.
d = batched_encoder(data.reshape(-1, 1), theta)
print("Average mu = ", np.mean(d[..., 0]), "Average std dev = ", np.mean(d[..., 1]))
Average mu = -0.18786085 Average std dev = 0.13066807
Surprisingly poor. This gets at one of the issues with VAEs: sometimes your KL will dominate and you have poor reconstruction and other times reconstruction will dominate. It just depends on the variance of your features, dimensions, and hyperparameters. You’ll often want to explicitly balance those terms to better agree with your goals for constructing the VAE.
14.7. Bead-Spring Polymer VAE#
Now we’ll move on to a more realistic system. We’ll use a bead-spring polymer as shown in the short trajectory snippet below.
This polymer has each bead (atom) joined by a harmonic bond, a harmonic angle between each three, and a Lennard-Jones interaction potential. Knowing these items will not be necessary for the example. We’ll construct a VAE that can compress the trajectory to some latent space and generate new conformations.
To begin, we’ll use the lessons learned from Input Data & Equivariances about how to align points from a trajectory. This will then serve as our training data. The space of our problem will be 12 2D vectors. Our system need not be permutation invariant, so we can flatten these vectors into a 24 dimensional input. The code belows loads and aligns the trajectory
urllib.request.urlretrieve(
"https://github.com/whitead/dmol-book/raw/main/data/long_paths.npz",
"long_paths.npz",
)
paths = np.load("long_paths.npz")["arr"]
# transform to be rot/trans invariant
data = align_principle(center_com(paths))
cmap = plt.get_cmap("cool")
for i in range(0, data.shape[0], 16):
plt.plot(data[i, :, 0], data[i, :, 1], "-", alpha=0.1, color="C2")
plt.title("All Frames")
plt.xticks([])
plt.yticks([])
plt.show()

Before training, let’s examine some of the marginals of the data. Marginals mean we’ve transformed (by integration) our probability distribution to be a function of only 1-2 variables so that we can plot nicely. We’ll look at the pairwise distance between points.
fig, axs = plt.subplots(ncols=4, squeeze=True, figsize=(16, 4))
for i, j in enumerate(range(1, 9, 2)):
axs[i].set_title(f"Dist between 0-{j}")
sns.distplot(np.linalg.norm(data[:, 0] - data[:, j], axis=1), ax=axs[i])
plt.tight_layout()
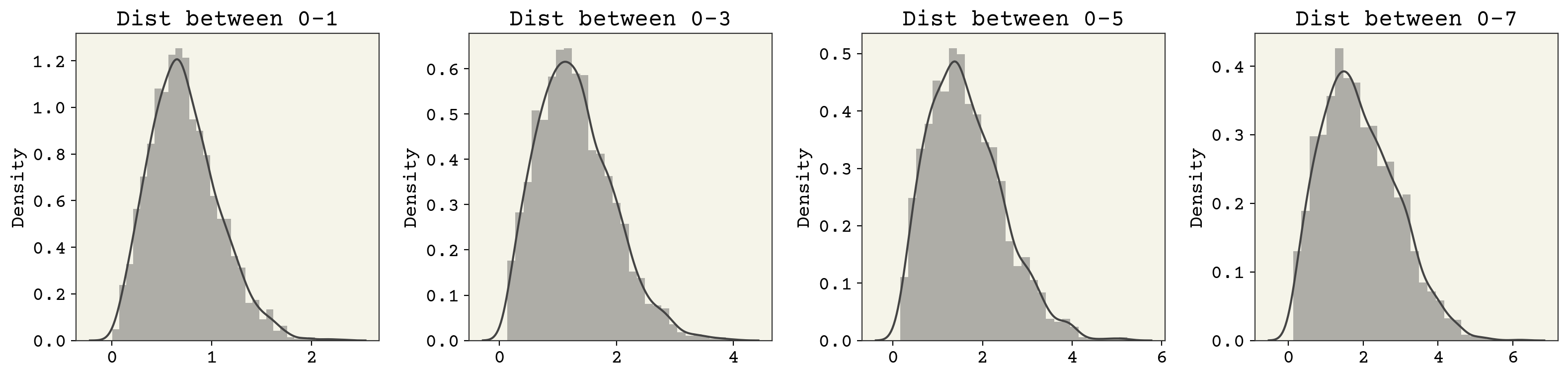
These look a little like the chi distribution with two degrees of freedom. Notice that the support (x-axis) changes between them though. We’ll keep an eye on these when we evaluate the efficacy of our VAE.
14.7.1. VAE Model#
We’ll build the VAE like above. I will make two changes. I will use JAX’s random number generator and I will make the number of layers variable. The code is hidden below, but you can expand to see the details. We’ll be starting with 4 layers total (3 hidden) with a hidden layer dimension of 256. Another detail is that we flatten the input/output since the order is preserved and thus we do not worry about separating the x,y dimension out.
14.7.2. Loss#
The loss function is similar to above, but I will not even bother with the Gaussian outputs. You can see the only change is that we drop the output Gaussian standard deviation from the loss, which remember was not trainable anyway.
@jax.jit
def loss(x, theta, phi, rng_key):
"""VAE Loss"""
# reconstruction loss
sampled_z_params = encoder(x, phi)
# reparameterization trick
# we use standard normal sample and multiply by parameters
# to ensure derivatives correctly propogate to encoder
sampled_z = (
jax.random.normal(rng_key, shape=(latent_dim,)) * sampled_z_params[:, 1]
+ sampled_z_params[:, 0]
)
# MSE now instead
xp = decoder(sampled_z, theta)
rloss = jnp.sum((xp - x) ** 2)
# LK loss
klloss = (
-0.5
- jnp.log(sampled_z_params[:, 1] + 1e-8)
+ 0.5 * sampled_z_params[:, 0] ** 2
+ 0.5 * sampled_z_params[:, 1] ** 2
)
# combined
return jnp.array([rloss, jnp.mean(klloss)])
# update compiled functions
batched_loss = jax.vmap(loss, in_axes=(0, None, None, None), out_axes=0)
batched_decoder = jax.vmap(decoder, in_axes=(0, None), out_axes=0)
batched_encoder = jax.vmap(encoder, in_axes=(0, None), out_axes=0)
grad = jax.grad(modified_loss, (1, 2))
fast_grad = jax.jit(grad)
fast_loss = jax.jit(batched_loss)
14.7.3. Training#
Finally comes the training. The only changes to this code are to flatten our input data and shuffle to prevent the each batch from having similar conformations.
batch_size = 32
epochs = 250
key = jax.random.PRNGKey(0)
flat_data = data.reshape(-1, input_dim)
# scramble it
flat_data = jax.random.permutation(key, flat_data)
opt_init, opt_update, get_params = optimizers.adam(step_size=1e-2)
theta0, key = init_theta(input_dim, hidden_units, latent_dim, num_layers, key)
phi0, key = init_phi(input_dim, hidden_units, latent_dim, num_layers, key)
opt_state = opt_init((theta0, phi0))
losses = []
# KL/Reconstruction balance
beta = 0.01
for e in range(epochs):
for bi, i in enumerate(range(0, len(flat_data), batch_size)):
# make a batch into shape B x 1
batch = flat_data[i : (i + batch_size)].reshape(-1, input_dim)
# udpate random number key
key, subkey = jax.random.split(key)
# get current parameter values from optimizer
theta, phi = get_params(opt_state)
last_state = opt_state
# compute gradient and update
grad = fast_grad(batch, theta, phi, key, beta)
opt_state = opt_update(bi, grad, opt_state)
# use large batch for tracking progress
lvalue = jnp.mean(fast_loss(flat_data[:100], theta, phi, subkey), axis=0)
losses.append(lvalue)
plt.plot([l[0] for l in losses], label="Reconstruction")
plt.plot([l[1] for l in losses], label="KL")
plt.plot([l[1] + l[0] for l in losses], label="ELBO")
plt.legend()
plt.ylim(0, 20)
plt.xlabel("epoch")
plt.ylabel("loss")
plt.show()
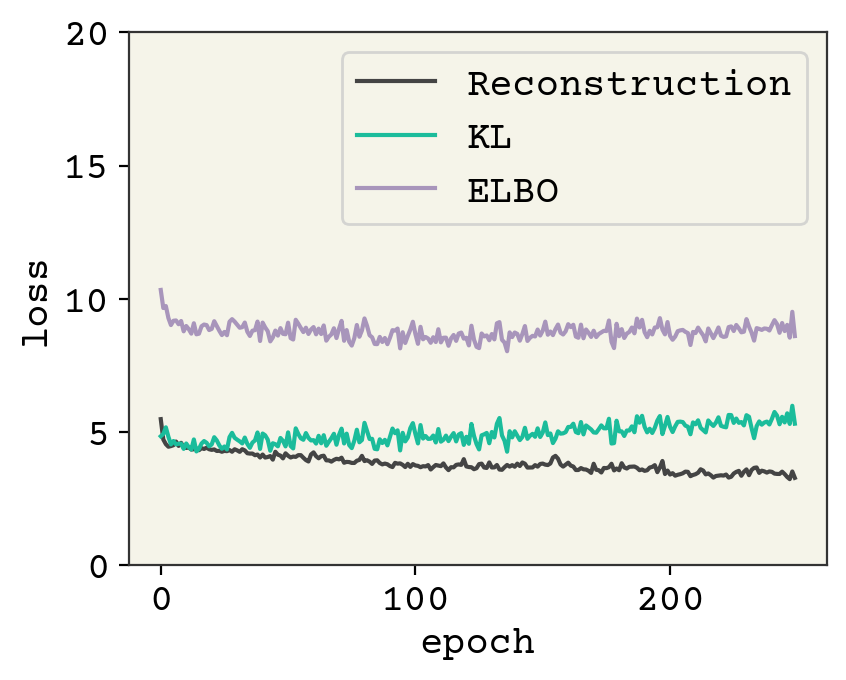
As usual, this model is undertrained. A latent space of 2, which we chose for plotting convenience, is also probably a little too compressed. Let’s sample a few conformation and see how they look.
sampled_data = decoder(jax.random.normal(key, shape=[latent_dim]), theta).reshape(-1, 2)
plt.plot(sampled_data[:, 0], sampled_data[:, 1], "-o", alpha=1)
plt.xticks([])
plt.yticks([])
plt.show()
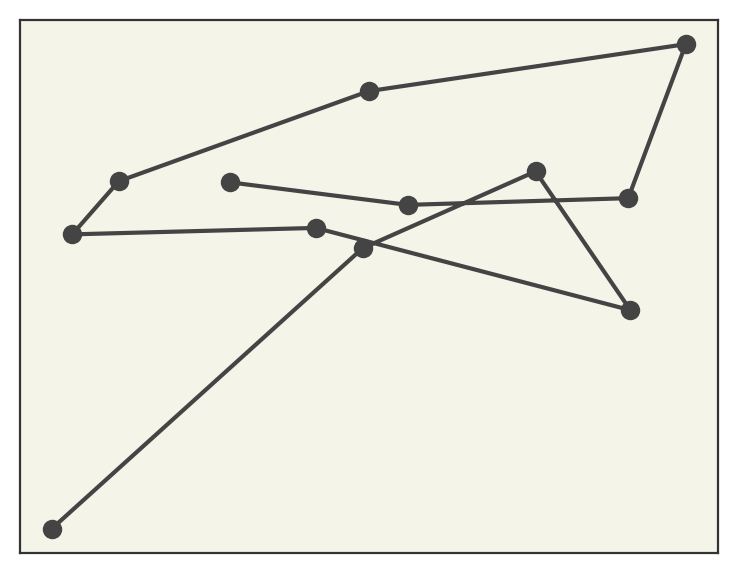
These look reasonable compared with the trajectory video showing the training conformations.
14.8. Using VAE on a Trajectory#
There are three main things to do with a VAE on a trajectory. The first is to go from a trajectory in the feature dimension to the latent dimension. This can simplify analysis of dynamics or act as a reaction coordinate for free energy methods. The second is to generate new conformations. This could be used to fill-in under sampling or perhaps extrapolate to new regions of latent space. You can also use the VAE to examine marginals that are perhaps under-sampled. Finally, you can do optimization on the latent space. For example, you could try to find the most compact structure. We’ll examine these examples but there are many other things you could examine. For a more complete model example with attention and 3D coordinates, see Winter et al. [WNoeC21]. You can find applications of VAEs on trajectories for molecular design [SMS+20], coarse-graining [WGomezB19], and identifying rare-events [RBWT18].
14.8.1. Latent Trajectory#
Let’s start by computing a latent trajctory. I’m going to load a shorter trajectory which has the frames closer together in time.
urllib.request.urlretrieve(
"https://github.com/whitead/dmol-book/raw/main/data/paths.npz", "paths.npz"
)
paths = np.load("paths.npz")["arr"]
short_data = align_principle(center_com(paths))
# get latent params
# throw away standard deviation
latent_traj = batched_encoder(short_data.reshape(-1, input_dim), phi)[:, 0]
plt.plot(latent_traj[:, 0], latent_traj[:, 1], "-o", markersize=5, alpha=0.5)
plt.show()
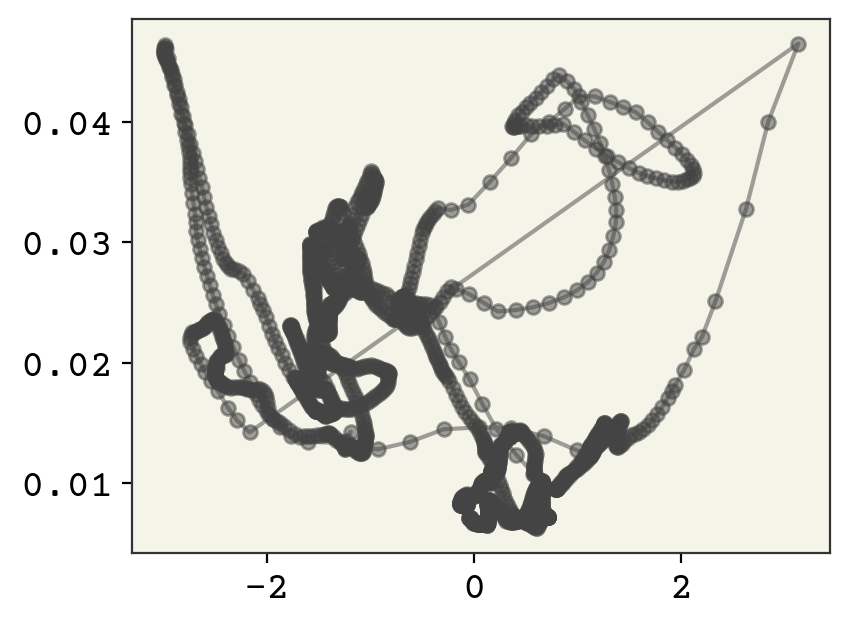
You can see that the trajectory is relatively continuous, except for a few wide jumps. We’ll see below that this is because the alignment process can have big jumps as our principle axis rapidly moves when the points rearrange. Let’s compare the video and the z-path side-by-side. You can find the code for this movie on the github repo.
You can see the quick change is due to our alignment quickly changing. This is why aligning on the principle axis isn’t always perfect: your axis can flip 90 degrees because the internal points change the moment of inertia enough to change.
14.8.2. Generate New Samples#
Let’s see how our samples look.
fig, axs = plt.subplots(ncols=2, figsize=(12, 4))
sampled_data = batched_decoder(
np.random.normal(size=(data.shape[0], latent_dim)), theta
).reshape(data.shape[0], -1, 2)
for i in range(0, data.shape[0]):
axs[0].plot(data[i, :, 0], data[i, :, 1], "-", alpha=0.1, color="C1")
axs[1].plot(
sampled_data[i, :, 0], sampled_data[i, :, 1], "-", alpha=0.1, color="C1"
)
axs[0].set_title("Training")
axs[1].set_title("Generated")
for i in range(2):
axs[i].set_xticks([])
axs[i].set_yticks([])
plt.show()
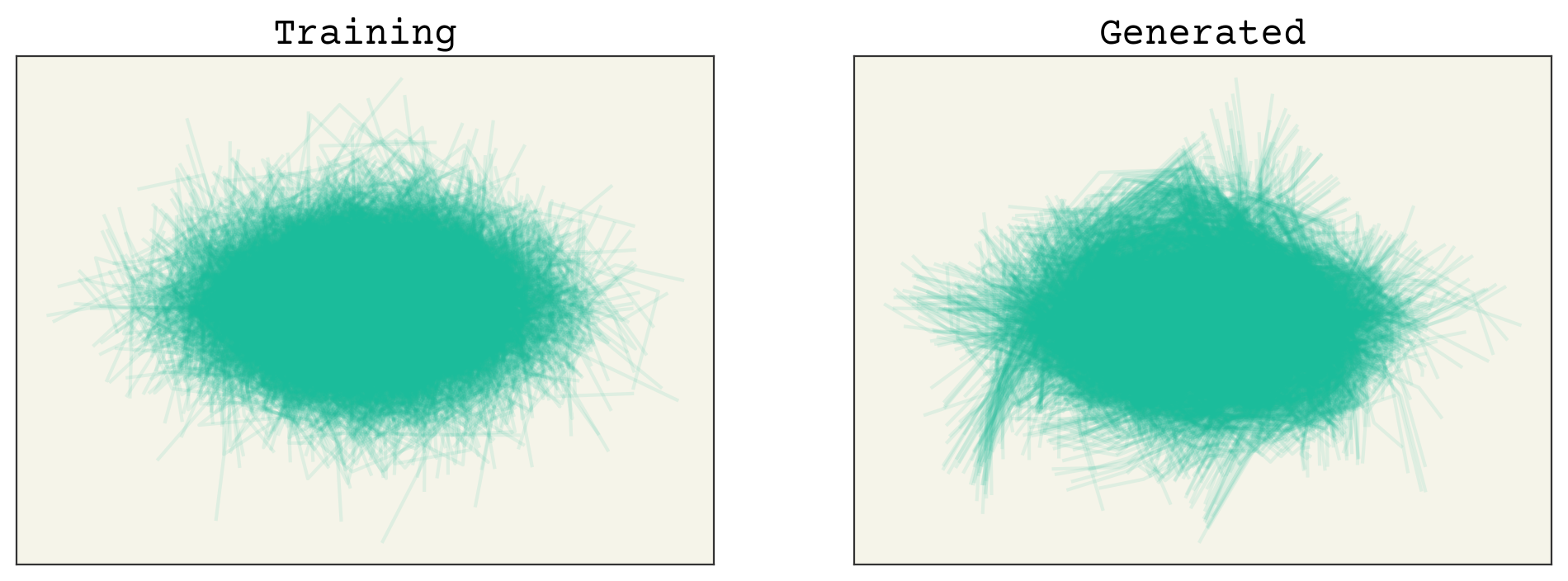
The samples are not perfect, but we’re close. Let’s examine the marginals.
fig, axs = plt.subplots(ncols=4, squeeze=True, figsize=(16, 4))
for i, j in enumerate(range(1, 9, 2)):
axs[i].set_title(f"Dist between 0-{j}")
sns.distplot(np.linalg.norm(data[:, 0] - data[:, j], axis=1), ax=axs[i])
sns.distplot(
np.linalg.norm(sampled_data[:, 0] - sampled_data[:, j], axis=1),
ax=axs[i],
hist=False,
)
plt.tight_layout()
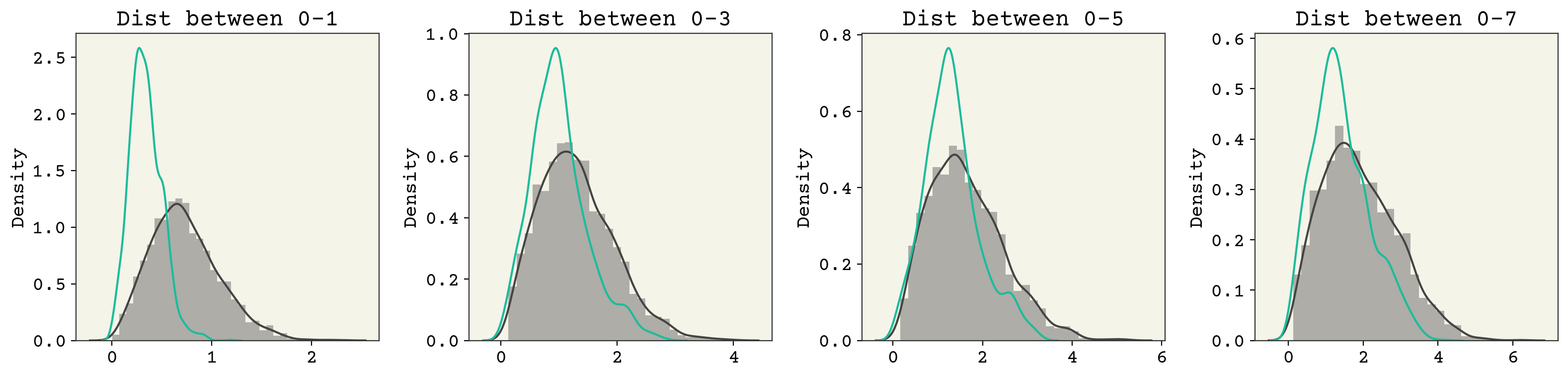
You can see that there are some issues here as well. Remember that our latent space is quite small: 2D. So we should not be that surprised that we’re losing information from our 24D input space.
14.8.3. Optimization on Latent Space#
Finally, let us examine how we can optimize in the latent space. Let’s say I want to find the most compact structure. We’ll define our loss function as the radius of gyration and take its derivative with respect to \(z\). Recall the definition of radius of gyration is
where \(r_i\) is distance to center of mass. Our generated samples are, by definition, centered at the origin though so we do not need to worry about center of mass. We want to take derivatives in \(z\), but need samples in \(x\) to compute radius of gyration. We use the decoder to get an \(x\) and can propagate derivatives through it, because it is a differentiable neural network.
def rg_loss(z):
x = decoder(z, theta).reshape(-1, 2)
rg = jnp.sum(x**2)
return jnp.sqrt(rg)
rg_grad = jax.jit(jax.grad(rg_loss))
Now we will find the \(z\) that minimizes the radius of gyration by using gradient descent with the derivative.
z = jax.random.normal(key, shape=[latent_dim])
losses = []
eta = 1e-2
for i in range(100):
losses.append(rg_loss(z))
g = rg_grad(z)
z -= eta * g
plt.plot(losses)
plt.xlabel("Iterations")
plt.ylabel("$R_g$")
plt.show()
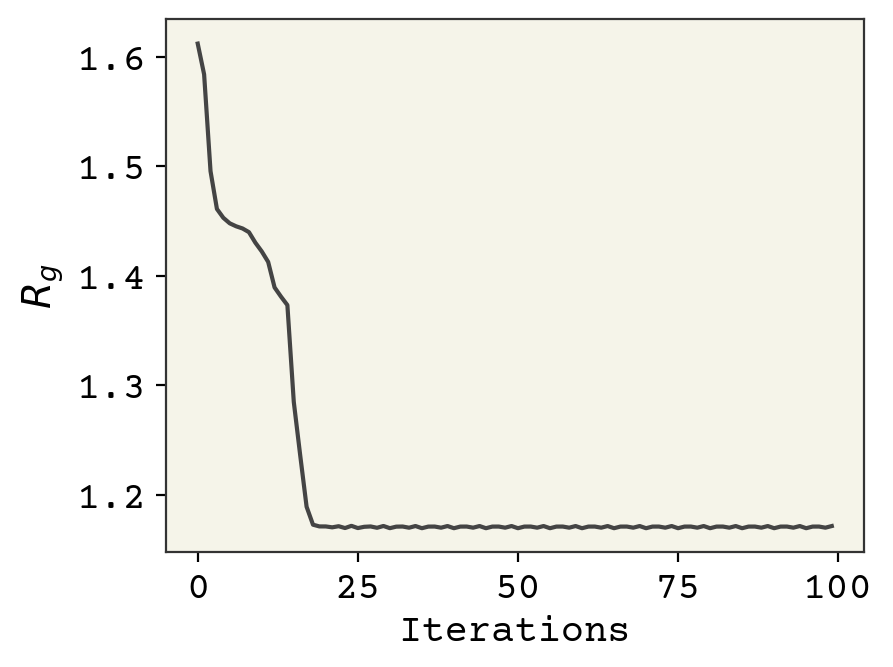
We have a \(z\) with a very low radius of gyration. How good is it? Well, we can also see what was the lowest radius of gyration observed structure in our trajectory. We compare them below.
# get min from training
train_rgmin = np.argmin(np.sum(data**2, axis=(1, 2)))
# use new z
opt_rgmin = decoder(z, theta).reshape(-1, 2)
plt.plot(
data[train_rgmin, :, 0], data[train_rgmin, :, 1], "o-", label="Training", alpha=0.8
)
plt.plot(opt_rgmin[:, 0], opt_rgmin[:, 1], "o-", label="Optimized", alpha=0.8)
plt.xticks([])
plt.yticks([])
plt.legend()
plt.show()
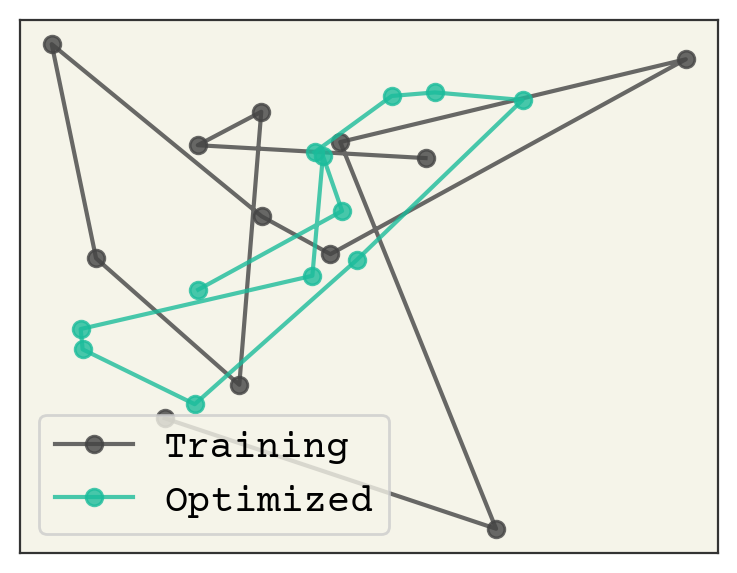
What is remarkable about this is that the optimized one has no overlaps and still reasonable bond-lengths. It is also more compact than the lowest radius of gyration found in the training example.
14.9. Relevant Videos#
14.9.1. Using VAE for Coarse-Grained Molecular Simulation#
14.9.2. Using VAE for Molecular Graph Generation#
14.9.3. Review of Molecular Graph Generative Models (including VAE)#
14.10. Chapter Summary#
A variational autoencoder is a generative deep learning model capable of unsupervised learning. It is capable of of generating new data points not seen in training.
A VAE is a set of two trained conditional probability distributions that operate on examples from the data \(x\) and the latent space \(z\). The encoder goes from data to latent and the decoder goes from latent to data.
The loss function is the log likelihood that we observed the training point \(x_i\).
Taking the log allows us to sum/average over data to aggregate multiple points.
The VAE can be used for both discrete or continuous features.
The goal with VAE is to reproduce the probability distribution of \(x\). Comparing the distribution over \(z\) and that of \(x\) allows us to evaluate how well the VAE operates.
A bead-spring polymer VAE example shows how VAEs operate on a trajectory.
14.11. Cited References#
Diederik P Kingma and Max Welling. Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114, 2013.
Emile Mathieu, Tom Rainforth, N Siddharth, and Yee Whye Teh. Disentangling disentanglement in variational autoencoders. In International Conference on Machine Learning, 4402–4412. PMLR, 2019.
Robin Winter, Frank Noé, and Djork-Arné Clevert. Auto-encoding molecular conformations. arXiv preprint arXiv:2101.01618, 2021.
Kirill Shmilovich, Rachael A Mansbach, Hythem Sidky, Olivia E Dunne, Sayak Subhra Panda, John D Tovar, and Andrew L Ferguson. Discovery of self-assembling π-conjugated peptides by active learning-directed coarse-grained molecular simulation. The Journal of Physical Chemistry B, 124(19):3873–3891, 2020.
Wujie Wang and Rafael Gómez-Bombarelli. Coarse-graining auto-encoders for molecular dynamics. npj Computational Materials, 5(1):1–9, 2019.
João Marcelo Lamim Ribeiro, Pablo Bravo, Yihang Wang, and Pratyush Tiwary. Reweighted autoencoded variational bayes for enhanced sampling (rave). The Journal of chemical physics, 149(7):072301, 2018.