11. Explaining Predictions#
Neural network predictions are not interpretable in general. In this chapter, we explore how to explain predictions. This is part of the broader topic of explainable AI (XAI). These explanations should help us understand why particular predictions are made. This is a critical topic because being able to understand model predictions is justified from a practical, theoretical, and increasingly a regulatory stand-point. It is practical because it has been shown that people are more likely to use predictions of a model if they can understand the rationale [LS04]. Another practical concern is that correctly implementing methods is much easier when one can understand how a model arrived at a prediction. A theoretical justification for transparency is that it can help identify incompleteness in model domains (i.e., covariate shift)[DVK17]. It is now becoming a compliance problem because both the European Union [GF17] and the G20 [Dev19] have recently adopted guidelines that recommend or require explanations for machine predictions. The US and EU are also considering going further with more strict draft legislation and a so-called White House AI Bill of Rights [BB22].
Audience & Objectives
This chapter builds on Standard Layers and Deep Learning on Sequences. It also assumes a good knowledge of probability theory, including conditional probabilities. You can read my notes or any introductory probability text to get an overview. After completing this chapter, you should be able to
Justify why explanations are important
Distinguish between justification, interpretation, and explanation
Compute feature importance and Shapley values
Define a counterfactual and compute them
Know which models are interpretable and how to fit interpretable surrogate models
A famous example on the need for explainable AI is found in Caruana et al.[CLG+15] who built an ML predictor to assess mortality risk of patients in the ER with pneumonia. The idea is that patients with pneumonia are screened with this tool and it helps doctors know which patients are more at risk of dying. It was found to be quite accurate. When the interpretation of its predictions were examined though, the reasoning was medically insane. The model surprisingly suggested patients with asthma (called asthmatics) have a reduced mortality risk when coming to the ER with pneumonia. Asthma, a condition which makes it difficult to breathe, was found to make pneumonia patients less likely to die. This was incidental; asthmatics are actually more at risk of dying from pneumonia but doctors are acutely aware of this and are thus more aggressive and attentive with them. Thanks to the increase care and attention from doctors, there are fewer mortalities. From an empirical standpoint, the model predictions are correct. However if the model were put into practice, it could have cost lives by incorrectly characterizing asthmatics as low mortality risk. Luckily the interpretability of their model helped researchers identify this problem. Thus, we can see that interpretation should always be a step in the construction of predictive models.
11.1. What is an explanation?#
We’ll use the definition of explanation from Miller [Mil19]. Miller distinguishes between interpretability, justification, and explanation with the following definitions:
interpretability “the degree to which an observer can understand the cause of a decision”. Miller considers this synonymous with explainability. This is generally a property of a model.
justification evidence or explanation of why a decision is good, like testing error or accuracy of a model. This is a property of a model.
explanation explanations are a presentation of information intended for humans that give the context and cause for an outcome. These are the major focus of this chapter. This is generally something extra we generate and not a property of a model.
We will dig deeper into what constitutes an explanation, but note an explanation is different than justifying a prediction. Justification is what we’ve focused on previously: empirical evidence for why we should believe model predictions are accurate. An explanation provides a cause for the prediction. Ultimately, explanations are intended to be understood by humans.
Deep learning alone is a black box modeling technique. It is not interpretable or explainable. Examining the weights or model equation provides little insight into why predictions are made. Thus, interpretability is an extra task and means adding an explanation to predictions from the model. This is a challenge because of both the black box nature of deep learning and because there is no consensus on what exactly constitutes an “explanation” for model predictions [DVK17]. For some, interpretability means having a natural language explanation justifying each prediction. For others, it can be simply showing which features contributed most to the prediction.
There are two broad approaches to interpretation of ML models: post hoc interpretation via explanations and self-explaining models [MSK+19]. Self-explaining models are constructed so that an expert can view output of the model and connect it with the features through reasoning. They are inherently interpretable. Self-explaining models are highly dependent on the task model[MSMuller18]. A familiar example would be a physics based simulation like molecular dynamics or a single-point quantum energy calculation. You can examine the molecular dynamics trajectory, look at output numbers, and an expert can explain why, for example, the simulation predicts a drug molecule will bind to a protein.
It may seem like self-explaining models would be useless for deep learning interpretation. However, we will see later that we can create a surrogate model (sometimes proxy model) that is self-explaining and train it to agree with the deep learning model. Why will this training burden be any less than just using the surrogate model from the beginning? We can generate an infinite amount of training data because our trained neural network can label arbitrary points. You can also construct deep learning models which have self-explaining features in them, like attention [BCB14]. This allows you to connect the input features to the prediction based on attention. There is also work within machine learning called symbolic regression, which tries to construct self-explaining models by working with mathematical equations that can be directly interpreted[AGFW21, BD00, UT20]. Symbolic regression is then used to generate the surrogate model[CSGB+20].
Post hoc interpretation by creating explanations can be approached in a number of ways, but the most common are training data importance, feature importance, and counterfactual explanations[WSW22, RSG16a, RSG16b, WMR17]. An example of a post hoc interpretation based on data importance is identifying the most influential training data to explain a prediction [KL17]. It is perhaps arguable if this gives an explanation, but it certainly helps understand which data is relevant for a prediction. Feature importance is probably the most common XAI approach and frequently appears in computer vision research where the pixels most important for the class of an image are highlighted.
Counterfactual explanations are an emerging post hoc interpretation method. Counterfactuals are new data point that serve as an explanation. A counterfactual gives insight into how important and sensitive the features are. An example might be in a model that recommends giving a loan. A model could produce the following counterfactual explanation (from [WMR17]):
You were denied a loan based on your annual income, zip code, and assets. If your annual income had been $45,000, you would have been offered a loan.
The second sentence is the conuterfactual and shows how the features could be changed to affect the model outcome. Counterfactuals provide a nice balance of complexity and explanatory power.
This was a brief overview of large field of XAI. You can find a recent review of interpretable deep learning in Samek et al. [SML+21] and Christopher Molnar has a broad online book about interpretable machine learning, including deep learning [Mol19]. Prediction error and confidence in predictions are not covered here, since they are more about justification, but see the methods from Regression & Model Assessment which apply.
11.2. Feature Importance#
Feature importance is the most straightforward and common method of interpreting a machine learning model. The output of feature importance is a ranking or numerical values for each feature, typically for a single prediction. If you are trying to understand the feature importance across the whole model, this is called global feature importance and local for a single prediction. Global feature importance and global interpretability is relatively rare because accurate deep learning models change which features are important in different regions of feature space.
Let’s start with a linear model to see feature importance:
where \(\vec{x}\) is our feature vector. A simple way to assess feature importance is to simply look at the weight value \(w_i\) for a particular feature \(x_i\). The weight \(w_i\) shows how much \(\hat{y}\) would change if \(x_i\) is increased by 1, while all other features are constant. If the magnitude of our features are comparable, then this would be a reasonable way to rank features. However, if our features have units, this approach is sensitive to unit choices and relative magnitude of features. For example if our temperature was changed from Celsius to Fahrenheit, a 1 degree increase will have a smaller effect.
To remove the effect of feature magnitude and units, a slightly better way to assess feature importance is to divide \(w_i\) by the standard error in the feature values. Recall that standard error is just the ratio of sum of squared error in predicted value divided by the total deviation in the feature. Standard error is a ratio of prediction accuracy to feature variance. \(w_i\) divided by standard error is called the \(t\)-statistic because it can be compared with the \(t\)-distribution for assessing feature importance.
where \(N\) is the number of examples, \(D\) is the number of features, and \(\bar{x}_i\) is the average value of the \(i\)th feature. The \(t_i\) value can be used to rank features and it can be used for a hypothesis test: if \(P(t > t_i) < 0.05\) then that feature is significant, where \(P(t)\) is Student’s \(t\)-distribution. Note that a feature’s significance is sensitive to which features are present in a model; if you add new features some may become redundant.
If we move to a nonlinear learned function \(\hat{f}(\vec{x})\), we must compute how the prediction changes if a feature value increases by 1 via the derivative approximation:
so a change by 1 is
In practice, we make a slight variation on this equation – instead of a Taylor series centered at 0 approximating this change, we center at some other root (point where the function is 0). This “grounds” the series at the decision boundary (a root) and then you can view the partials as “pushing” the predicted class away or towards the decision boundary. Another way to think about this is that we use the first-order terms of the Taylor series to build a linear model. Then we just apply what we did above to that linear model and use the coefficients as the “importance” of features. Specifically, we use this surrogate function for \(\hat{f}(\vec{x})\):
where \(\vec{x}'\) is the root of \(\hat{f}(\vec{x})\). In practice people may choose the trivial root \(\vec{x}' = \vec{0}\), however a nearby root is ideal. This root is often called the baseline input. Note that as opposed to the linear example above, we consider the product of the partial \(\frac{\partial \hat{f}(\vec{x})}{\partial x_i}\) and the increase above baseline \((x_i - x_i')\).
11.2.1. Neural Network Feature Importance#
In neural networks, the partial derivatives are a poor approximation of the real changes to the output. Small changes to the input can have discontinuous changes (because of nonlinearities like ReLU), making the terms above have little explanatory power. This is called the shattered gradients problem [BFL+17]. Breaking down each feature separately also misses correlations between features – which don’t exist in a linear model. Thus the derivative approximation works satisfactorily in locally linear models, but not deep neural networks.
There are a variety of techniques that get around the issue of shattered gradients in neural networks. Two popular methods are integrated gradients [STY17] and SmoothGrad[STK+17]. Integrated gradients creates a path from \(\vec{x}'\) to \(\vec{x}\) and integrates Equation 4 along that path:
where \(t\) is some increment along the path such that \(\vec{x}' + t\left(\vec{x} - \vec{x}'\right) = \vec{x}'\) when \(t = 0\) and \(\vec{x}' + t\left(\vec{x} - \vec{x}'\right) = \vec{x}\) when \(t = 1\). This gives us the integrated gradient for each feature \(i\). The integrated gradients are the importance of each feature, but without the complexity of shattered gradients. There are some nice properties too, like \(\sum_i \textrm{IG}_i = f(\vec{x}) - f(\vec{x}')\) so that the integrated gradients provide a complete partition of the change from the baseline to the prediction[STY17].
Implementing integrated gradients is actually relatively simple. You approximate the path integral with a Riemann sum by breaking the path into a set of discrete inputs between the input features \(\vec{x}\) and the baseline \(\vec{x}'\). You compute the gradient of these inputs with the neural network. Then you multiply that by the change in features above baseline: \(\left(\vec{x} - \vec{x}'\right)\).
SmoothGrad is a similar idea to the integrated gradients. Rather than summing up the gradients along a path though, we sum gradients from random points nearby our prediction. The equation is:
where \(M\) is a choice of sample number and \(\vec{\epsilon}\) is sampled from \(D\) zero-mean Guassians [STK+17]. The only change in implementation here is to replace the path with a series of random perturbations.
Beyond these gradient based approaches, Layer-wise Relevance Propagation (LRP) is another popular approach for feature importance analysis in neural networks. LRP works by doing a backwards propogation through the neural network that partitions the output value of one layer to the input features. It “distributes relevance.” What is unusual about LRP is that each layer type needs its own implementation. It doesn’t rely on the analytic derivative, but instead a Taylor series expansion of the layer equation. There are variants for GNNs and sequence models, so that LRP can be used in most settings in materials and chemistry [MBL+19].
11.2.2. Shapley Values#
A model agnostic way to treat feature importance is with Shapley values. Shapley values come from game theory and are a solution to how to pay a coalition of cooperating players according to their contributions. Imagine each feature is a player and we would like to “pay” them according to their contribution to the predicted value. A Shapley value \(\phi_i(x)\) is the pay to feature \(i\) at instance \(x\). We break-up the predicted function value \(\hat{f}(x)\) into the Shapley values so that the sum of the pay is the function value: \(\sum_i \phi_i(x) = \hat{f}(x)\). This means you can interpret the Shapley value of a feature as its numerical contribution to the prediction. Shapley values are powerful because their calculation is agnostic to the model, they partition the predicted value among each feature, and they have other attributes that we would desire in an explanation of a prediction (symmetry, linearity, permutation invariant, etc.). Their disadvantage are that exact computation is combinatorial with respect to feature number and they have no sparsity, making them less helpful as feature number grows. Most methods we discuss here also have no sparsity. You can always force your model to be sparse to achieve sparse explanations, like with L1 regularization (see Standard Layers).
Shapley values are computed as
where \(S \in N \backslash x_i\) means all sets of features that exclude feature \(x_i\), \(S\cup x_i\) means putting back feature \(x_i\) into the set, and \(v(S)\) is the value of \(\hat{f}(x)\) using only the features included in \(S\), and \(Z\) is a normalization value. The formula can be interpreted as the mean of all possible differences in \(\hat{f}\) formed by adding/removing feature \(i\).
One immediate concern though is how can we “remove” feature \(i\) from a model equation? We marginalize out feature \(i\). Recall a marginal is a way to integrate out a random variable \(P(x) = \int\, P(x,y)\,dy\). That integrates over all possible \(x\) values. Marginalization can be used on functions of random variables, which obviously are also random variables, by taking an expectation: \(E_y[f | X = x] = \int\,f(X=x,y)P(X=x,y)\, dy\). I’ve emphasized that the random variable \(X\) is fixed in the integral and thus \(E_y[f]\) is a function of \(x\). \(y\) is removed by computing the expected value of \(f(x,y)\) where \(x\) is fixed (the function argument). We’re essentially replacing \(f(x,y)\) with a new function \(E_y[f]\) that is the average of all possible \(y\) values. I’m over-explaining this though, it’s quite intuitive once you see the code below. The other detail is that value is the change relative to the average of \(\hat{f}\). You can typically ignore this extra term - it cancels, but I include it for completeness. Thus the value equation becomes [vStrumbeljK14]:
How do we compute the marginal \(\int\,f(x_0, x_1, \ldots, x_i,\ldots, x_N)P(x_0, x_1, \ldots, x_i,\ldots, x_N)\, dx_i\)? We do not have a known probability distribution \(P(\vec{x})\). We can sample from \(P(\vec{x})\) by considering our data as an empirical distribution. That is, we can sample from \(P(\vec{x})\) by sampling data points. There is a little bit of complexity here because we need to sample the \(\vec{x}\)’s jointly, we cannot just mix together individual features randomly because there are correlations between features that will be removed.
Strumbelj et al. [vStrumbeljK14] showed that we can directly estimate the \(i\)th Shapley value with:
where \(\vec{z}\) is a “chimera” example constructed from the real example \(\vec{x}\) and a randomly drawn example \(\vec{x}'\). We randomly select from \(\vec{x}\) and \(\vec{x}'\) to construct \(\vec{z}\), except \(\vec{z}_{+i}\) specifically has the \(i\)th feature from the example \(\vec{x}\) and \(\vec{z}_{-i}\) has the \(i\)th feature from the random example \(\vec{x}'\). \(M\) is chosen large enough to get a good sample for this value. [vStrumbeljK14] gives guidance on choosing \(M\), but basically as large \(M\) as computationally feasible reasonable. One change in this approximation though is that we end-up with an explicit term for the expectation (sometimes denoted \(\phi_0\)) so that our “completeness” equation is:
Or if you explicitly include expectation as \(\phi_0\), which is independent of \(\vec{x}\)
With this efficient approximation method, the strong theory, and independence of model choice, Shapley values are an excellent choice for describing feature importance for predictions.
11.3. Running This Notebook#
Click the above to launch this page as an interactive Google Colab. See details below on installing packages.
Tip
To install packages, execute this code in a new cell.
!pip install dmol-book
If you find install problems, you can get the latest working versions of packages used in this book here
import flax.linen as fnn
import jax
import jax.numpy as jnp
import numpy as np
import matplotlib.pyplot as plt
import urllib
from functools import partial
from jax.example_libraries import optimizers as opt
import dmol
np.random.seed(0)
ALPHABET = [
"-",
"A",
"R",
"N",
"D",
"C",
"Q",
"E",
"G",
"H",
"I",
"L",
"K",
"M",
"F",
"P",
"S",
"T",
"W",
"Y",
"V",
]
We now define a few functions we’ll need to convert between amino acid sequence and one-hot vectors.
def seq2array(seq, L=200):
return np.pad(list(map(ALPHABET.index, seq)), (0, L - len(seq))).reshape(1, -1)
def array2oh(a):
a = np.squeeze(a)
o = np.zeros((len(a), 21))
o[np.arange(len(a)), a] = 1
return o.astype(np.float32).reshape(1, -1, 21)
urllib.request.urlretrieve(
"https://github.com/whitead/dmol-book/raw/main/data/hemolytic.npz",
"hemolytic.npz",
)
with np.load("hemolytic.npz", "rb") as r:
pos_data, neg_data = r["positives"], r["negatives"]
11.4. Feature Importance Example#
Let’s see an example of these feature importance methods on a peptide prediction task to predict if a peptide will kill red blood cells (hemolytic). This is similar to the solubility prediction example from Standard Layers. The data is from [BW21]. The model takes in peptides sequences (e.g., DDFRD) and predicts the probability that the peptide is hemolytic. The goal of the feature importance method here will be to identify which amino acids matter most for the hemolytic activity. The hidden-cell below loads and processes the data into a dataset.
We rebuild the convolution model in Jax (using Flax Linen) to make working with gradients a bit easier. We also make a few changes to the model – we pass in the sequence length and amino acid fractions as extra information in addition to the convolutions.
def binary_cross_entropy(logits, y):
"""Binary cross entropy without sigmoid. Works with logits directly"""
return (
jnp.clip(logits, 0, None) - logits * y + jnp.log(1 + jnp.exp(-jnp.abs(logits)))
)
class HemolyticModel(fnn.Module):
@fnn.compact
def __call__(self, x):
aa_fracs = jnp.mean(x, axis=1)[:, 1:]
mask = jnp.sum(x[..., 1:], axis=-1, keepdims=True)
for kernel, pool in zip([5, 3, 3], [4, 2, 2]):
x = fnn.Conv(16, (kernel,))(x) * mask
x = jax.nn.tanh(x)
x = fnn.max_pool(x, (pool,), (pool,))
mask = fnn.max_pool(mask, (pool,), (pool,))
x = jnp.concatenate(
(x.reshape(x.shape[0], -1), aa_fracs, jnp.sum(mask, axis=1)), axis=1
)
x = fnn.Dense(256, use_bias=False)(x)
x = jax.nn.tanh(x)
x = fnn.Dense(64, use_bias=False)(x)
x = jax.nn.tanh(x)
x = fnn.Dense(1, use_bias=False)(x)
return x
model = HemolyticModel()
def loss_fn(params, x, y):
logits = model.apply(params, x)
return jnp.mean(binary_cross_entropy(logits, y))
@jax.jit
def hemolytic_prob(params, x):
logits = model.apply(params, x)
return jax.nn.sigmoid(jnp.squeeze(logits))
@jax.jit
def accuracy_fn(params, x, y):
logits = model.apply(params, x)
return jnp.mean((logits >= 0) * y + (logits < 0) * (1 - y))
rng = jax.random.PRNGKey(0)
xi, yi = features[:batch_size], labels[:batch_size]
params = model.init(rng, xi)
opt_init, opt_update, get_params = opt.adam(1e-2)
opt_state = opt_init(params)
@jax.jit
def update(step, opt_state, x, y):
value, grads = jax.value_and_grad(loss_fn)(get_params(opt_state), x, y)
opt_state = opt_update(step, grads, opt_state)
return value, opt_state
epochs = 32
step = 0
for e in range(epochs):
avg_v = 0
for xi, yi in batch_iter(train_x, train_y, batch_size, shuffle=True):
v, opt_state = update(step, opt_state, xi, yi)
avg_v += v
step += 1
opt_params = get_params(opt_state)
def predict(x):
return jnp.squeeze(model.apply(opt_params, x))
def predict_prob(x):
return hemolytic_prob(opt_params, x)
If you’re having trouble following the code, that’s OK! The goal of this chapter is to show how to get explanations of a model, not necessarily how to build the model. So focus on the next few lines where I show how to use the model to get predictions and explain them. The model is called via predict(x) for logits or predict_prob for probability.
Let’s try some amino acid sequences to get a feel for the model. The model outputs logits (logarithm of odds), which we put through a sigmoid to get probabilities. The peptides must be converted from a sequence to a matrix of one-hot column vectors. We’ll try two sequences from the dataset: one labeled hemolytic and one non-hemolytic.
s = "LPRGIADLTENGAYQ"
sm = array2oh(seq2array(s))
p = predict_prob(sm)
print(f"Probability {s} of being hemolytic {p:.2f}")
s = "IKITTMLAKLGKVLAHV"
sm = array2oh(seq2array(s))
p = predict_prob(sm)
print(f"Probability {s} of being hemolytic {p:.2f}")
Probability LPRGIADLTENGAYQ of being hemolytic 1.00
Probability IKITTMLAKLGKVLAHV of being hemolytic 0.00
The model correctly identifies the hemolytic peptide with high probability and the non-hemolytic one with low probability. Now we compute the accuracy of our model, which is quite good.
acc = []
for xi, yi in batch_iter(test_x, test_y, batch_size):
acc.append(accuracy_fn(opt_params, xi, yi))
print(jnp.mean(np.array(acc)))
0.92083335
11.4.1. Gradients#
Now to start examining why a particular sequence is hemolytic! We’ll begin by computing the gradients with respect to input – the naieve approach that is susceptible to shattered gradients. Computing this is a component in the process for integrated and smooth gradients, so not wasted effort. We will use a hemolytic peptide from the dataset to get more interesting analysis.
s = "GHKLWYARGFMTNVTMKHQ"
sm = array2oh(seq2array(s))
p = predict_prob(sm)
print(f"Probability {s} of being hemolytic {p:.2f}")
Probability GHKLWYARGFMTNVTMKHQ of being hemolytic 1.00
The code is quite simple, just a gradient computation.
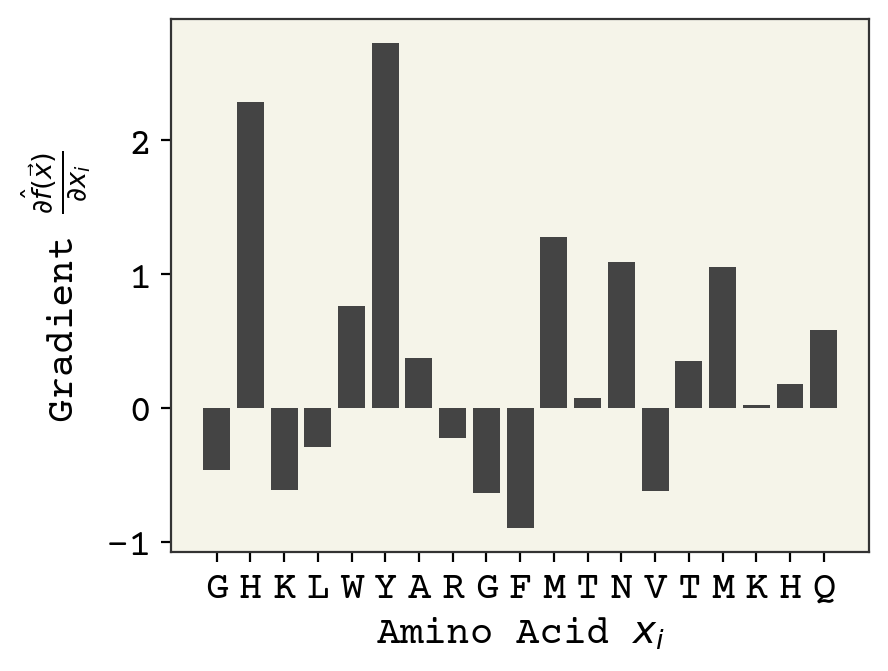
gradient = jax.grad(predict, 0)
g = gradient(sm)
plot_grad(g, s)
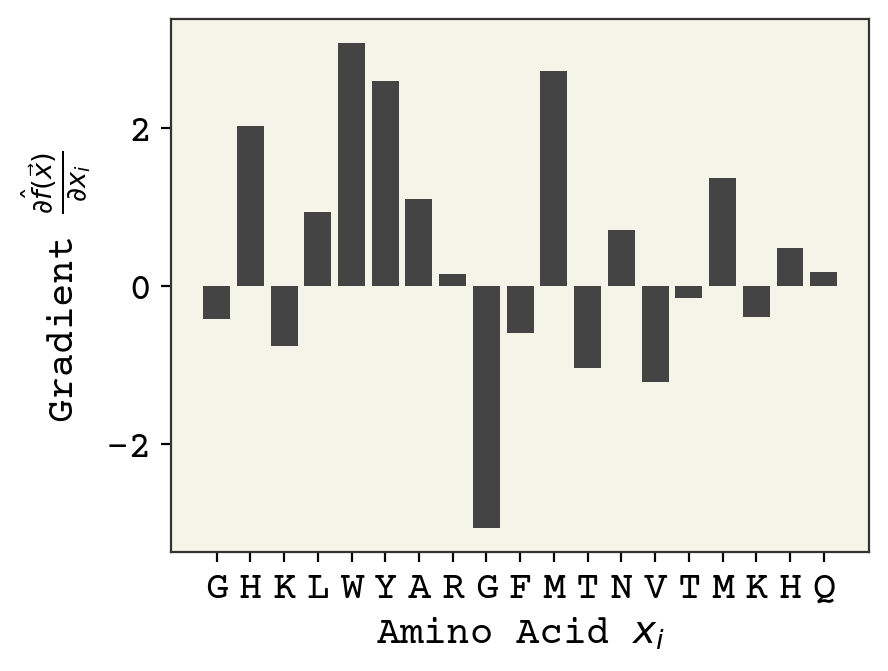
Remember that the model outputs logits. Positive value of the gradient mean this amino acid is responsible for pushing hemolytic probability higher and negative values mean the amino acid is pushing towards non-hemolytic. Interestingly, you can see a strong position dependence – the same amino acid type at different positions can have different importance.
11.4.2. Integrated Gradients#
We’ll now implement the integrated gradients method. We go through three basic steps:
Create an array of inputs going from baseline to input peptide
Evaluate gradient on each input
Compute the sum of the gradients and multiply it by difference between baseline and peptide
The baseline for us is all zeros – which gives a probability of 0.5 (logits = 0, a model root). This baseline is exactly on the decision boundary. You could use other baselines like all glycines or all alanines, just they should be at or near probability of 0.5. You can find a detailed and interactive exploration of the baseline choice in [SLL20].
def integrated_gradients(sm, N):
baseline = jnp.zeros((1, L, 21))
t = jnp.linspace(0, 1, N).reshape(-1, 1, 1)
path = baseline * (1 - t) + sm * t
def get_grad(pi):
# compute gradient
# add/remove batch axes
return gradient(pi[jnp.newaxis, ...])[0]
gs = jax.vmap(get_grad)(path)
# sum pieces (Riemann sum), multiply by (x - x')
ig = jnp.mean(gs, axis=0, keepdims=True) * (sm - baseline)
return ig
ig = integrated_gradients(sm, 1024)
plot_grad(ig, s)
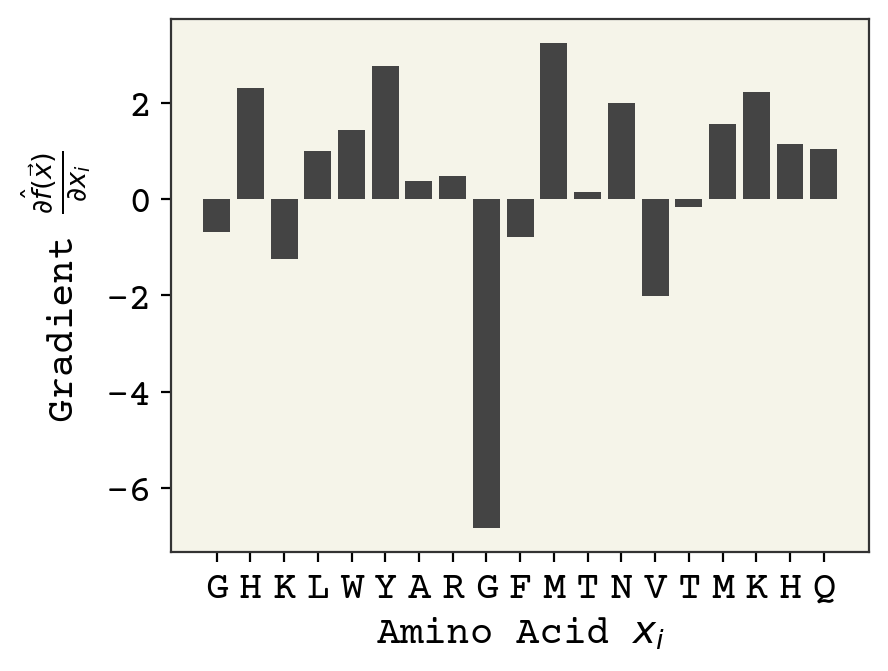
We see that the position dependence has become more pronounced, with arginine being very sensitive to position. Relatively little has qualitatively changed between this and the vanilla gradients.
11.4.3. SmoothGrad#
To do SmoothGrad, our steps are almost identicial:
Create an array of inputs that are random pertubations of the input peptide
Evaluate gradient on each input
Compute the mean of the gradients
There is one additional hyperparameter, \(\sigma\), which in principle should be as small as possible while still causing the model output to change.
def smooth_gradients(sm, N, rng, sigma=1e-3):
baseline = jnp.zeros((1, L, 21))
t = jax.random.normal(rng, shape=(N, sm.shape[1], sm.shape[2])) * sigma
path = sm + t
# remove examples that are negative and force summing to 1
path = jnp.clip(path, 0, 1)
path /= jnp.sum(path, axis=2, keepdims=True)
def get_grad(pi):
# compute gradient
# add/remove batch axes
return gradient(pi[jnp.newaxis, ...])[0]
gs = jax.vmap(get_grad)(path)
# mean
ig = jnp.mean(gs, axis=0, keepdims=True)
return ig
sg = smooth_gradients(sm, 1024, jax.random.PRNGKey(0))
plot_grad(sg, s)
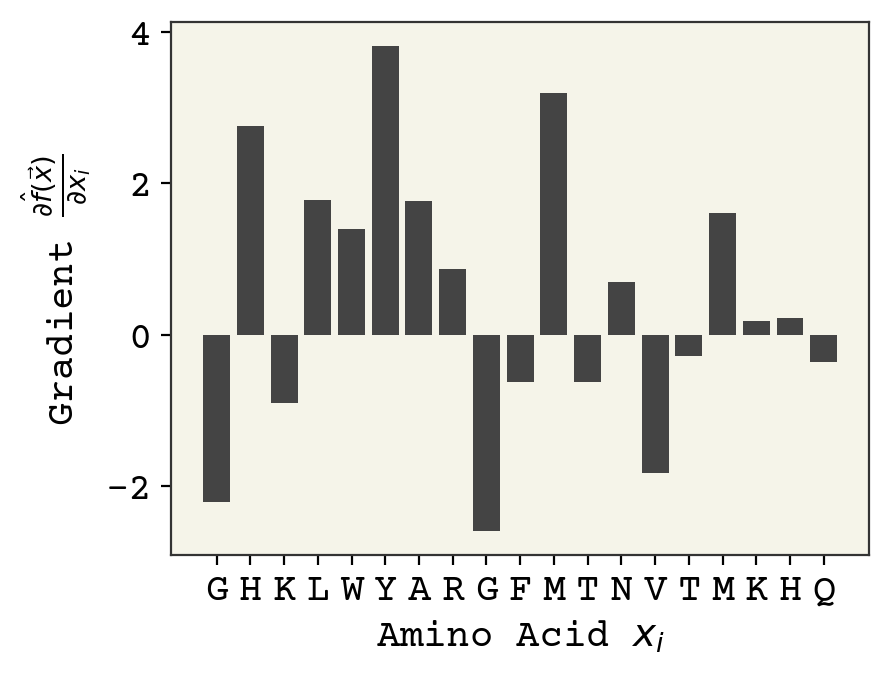
It looks remarkably similar to the vanilla gradient setting – probably because our 1D input/shallow network is not as sensitive to shattered gradients.
11.4.4. Shapley Value#
Now we will approximate the Shapley values for each feature using Equation 10.9. The Shapley value computation is different than previous approaches because it does not require gradients. The basic algorithm is:
select random point x’
sample a coalition size and coalition members with the Shapley kernel weighting
create point z by combining x and x’
compute change in predicted function
One efficiency change we make is to prevent modifying the sequence in its padding – basically prevent exploring making the sequence longer.
def shapley(i, sm, sampled_x, rng, model, sl):
M, F, *_ = sampled_x.shape
# sample coalitions with Shapley kernel weighting on non-padding features
# choose coalition size k uniformly in {0, ..., sl-1}
key_k, key_perm = jax.random.split(rng)
k = jax.random.randint(key_k, (M,), 0, max(sl, 1))
perm_keys = jax.random.split(key_perm, M)
perms = jax.vmap(lambda key: jax.random.permutation(key, sl))(perm_keys)
rank = jnp.argsort(perms, axis=1)
# members in S are chosen as first k entries of permutation, excluding i
in_s = rank < k[:, None]
in_s = in_s.at[:, i].set(False)
# begin with all features from sampled_x
z_choice = jnp.zeros((M, F), dtype=sm.dtype)
# keep padded positions fixed to sm
z_choice = z_choice.at[:, sl:].set(1.0)
# set coalition members to come from sm
z_choice = z_choice.at[:, :sl].set(in_s.astype(sm.dtype))
# construct with and w/o ith feature
z = sm * z_choice[..., jnp.newaxis] + sampled_x * (1 - z_choice[..., jnp.newaxis])
z_choice_i = z_choice.at[:, i].set(1.0)
z_i = sm * z_choice_i[..., jnp.newaxis] + sampled_x * (1 - z_choice_i[..., jnp.newaxis])
v = model(z_i) - model(z)
return jnp.squeeze(jnp.mean(v, axis=0))
# assume data is already shuffled, so just take M
M = 1024
sl = len(s)
sampled_x = train_x[:M]
# make batched shapley so we can compute for all features
bshapley = jax.vmap(shapley, in_axes=(0, None, None, 0, None, None))
sv = bshapley(
jnp.arange(sl),
sm,
sampled_x,
jax.random.split(jax.random.PRNGKey(0), sl),
predict,
sl,
)
# compute global expectation
eyhat = 0
count = 0
for xi, yi in batch_iter(features, labels, M):
eyhat += jnp.sum(predict(xi))
count += xi.shape[0]
eyhat /= count
One nice check on Shapley values is that we can check that their sum is equal to the value of model function minus the expect value across all instances. Note we made approximations to use the Equation from [vStrumbeljK14] so that we cannot expect perfect agreement. That value is computed as:
print(np.sum(sv), predict(sm))
7.0299134 7.6001244
which should now more closely match the completeness relation with finite-sample error. We can check that by examining how sample number affects the sum of Shapley values.
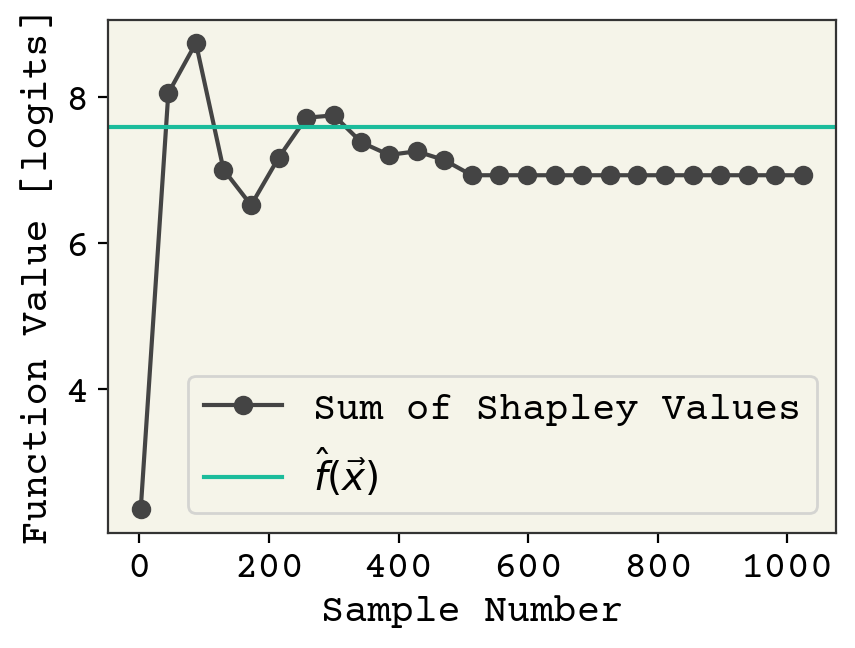
Fig. 11.1 A comparison of sum of Shapley values and function value as a function of samples number in the Shapley value approximation.#
It should converge as sample size increases. Finally we can view the individual Shapley values, which is our explanation.
plot_grad(sv, s)
The four methods are shown side-by-side below.
heights = []
plt.figure(figsize=(12, 4))
x = np.arange(len(s))
for i, (gi, l) in enumerate(zip([g, ig, sg], ["Gradient", "Integrated", "Smooth"])):
h = gi[0, np.arange(len(s)), list(map(ALPHABET.index, s))]
plt.bar(x + i / 5 - 1 / 4, h, width=1 / 5, edgecolor="black", label=l)
plt.bar(x + 3 / 5 - 1 / 4, sv, width=1 / 5, edgecolor="black", label="Shapley")
ax = plt.gca()
ax.set_xticks(range(len(s)))
ax.set_xticklabels(s)
ax.set_xlabel("Amino Acid $x_i$")
ax.set_ylabel(r"Importance [logits]")
plt.legend()
plt.show()
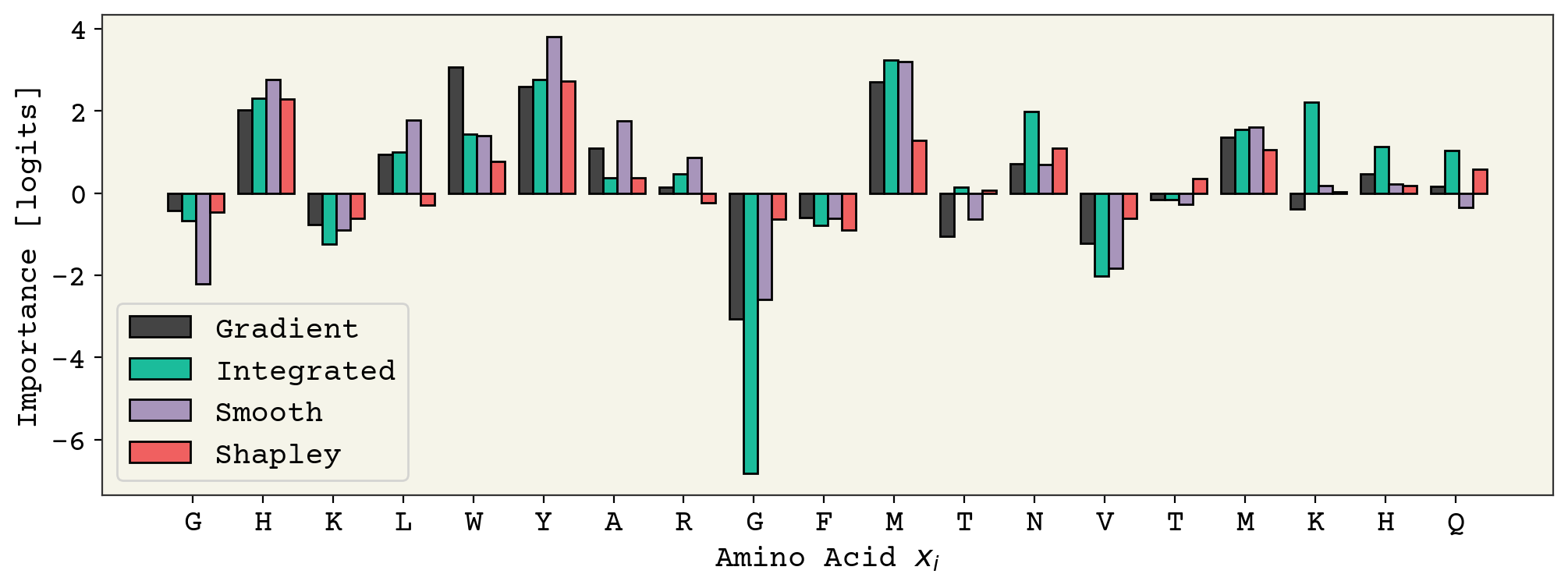
As someone who works with peptides, I believe the Shapley values are the most accurate here. Shapley values tend to give a smoother, more balanced view of feature importance than raw gradients.
What can we conclude from this information? We could perhaps add an explanation like this: “The sequence is predicted to be hemolytic primarily because of the tryptophan (W) and tyrosine (Y) residues.”
11.5. What is feature importance for?#
Feature importance rarely leads to a clear explanation that gives the cause for a prediction or insight that is actionable. The lack of causality can lead us to find meaning in feature explanations that do not exist[CK18]. Another caveat is remember that we are explaining model, not the actual chemical systems. For example, avoid saying “Hemolytic activity was caused by the glutamine in position 5.” Instead: “Our model predicted hemolytic activity because of glutamine in position 5.”
An actionable explanation is one that shows how to modify the features to affect the outcome — similar to saying we know the cause for an outcome. Thus, there is ongoing debate about if feature importance is an explanation [Lip18]. A popular line of work that tries to connect feature importance to human concepts is called Quantitative testing with concept activation vectors (TCAV) [KWG+18]. I personally have moved away from feature importance for XAI because the explanations are not actionable or causal and often can add additional confusion.
11.6. Training Data Importance#
Another kind of explanation or interpretation we might desire is which training data points contribute most to a prediction. This is a more literal answer to the question: “Why did my model predict this?” – neural networks are a result of training data and thus the answer to why a prediction is made can be traced to training data. Ranking training data for a given prediction helps us understand which training examples are causing the neural network to predict a value. This is like an influence function, \(\mathcal{I}(x_i, x)\), which gives a score of influence for training point \(i\) and input \(x\). The most straightforward way to compute the influence would be to train the neural network with (i.e., \(\hat{f}(x)\)) and without \(x_i\) (i.e., \(\hat{f}_{-x_i}(x)\)) and define the influence as
For example, if a prediction is higher after removing the training point \(x_i\) from training, we would say that point has a positive influence. Computing this influence function requires training the model as many times as you have points – typically computationally unfeasible. [KL17] show a way to approximate this by looking at infinitesimal changes to the weights of each training point. Computing these influence functions does require computing a Hessian with respect to the loss function and thus are not commonly used. If you’re using JAX though, this is simple to do.
Training data importance provides an interpretation that is useful for deep learning experts. It tells you which training examples are most influential for a given prediction. This can help troubleshoot issues with data or tracing explanations for spurious predictions. However, a typical user of predictions from a deep learning model will probably be unsatisfied with a ranking of training data as an explanation.
11.7. Surrogate Models#
One of the more general ideas in interpretability is to fit an interpretable model to a black box model in the neighborhood of a specific example. We assume that an interpretable model cannot be fit globally to a black box model – otherwise we could just use the interpretable model and throw away the black box model. However, if we fit the interpretable model to just a small region around an example of interest, we can provide an explanation through the locally correct interpretable model. We call the interpretable model a local surrogate model. Examples of local surrogate models that are inherently interpretable include decision trees, linear models, sparse linear models (for succinct explanations), a Naive Bayes Classifier, etc.
A popular algorithm for this process of fitting a local surrogate model is called Local Interpretable Model-Agnostic Explanations (LIME) [RSG16a]. LIME fits the local surrogate model in the neighborhood of the example of interest utilizing the loss function that trained the original black box model. The loss function for the local surrogate model is weighted so that we value points closer to the example of interest as we regress the surrogate model. The LIME paper includes sparsifying the surrogate model in its notation, but we’ll omit that from the loss equation since that is more of an attribute of the local surrogate model. Thus, our definition for the local surrogate model loss is
where \(w(x', x)\) is a weight kernel function that weights points near example of interest \(x\), \(\mathcal{l}(\cdot,\cdot)\) is the original black box model loss, \(\hat{f}(\cdot)\) is the black box model, and \(\hat{f}_s(\cdot)\) is the local surrogate model.
The weight function is a bit ad hoc – it depends on the data type. For regression tasks with scalar labels, we use a kernel function and you have a variety of choices: Gaussian, cosine, Epanechnikov. For text, the LIME implementations use a Hamming distance which just counts number of text tokens which do not match between two strings. Images use the same distance but with superpixels being the same as the example or blank.
How are the points \(x'\) generated? In the continuous case \(x'\) is sampled uniformly, which is quite a feat since feature spaces are often unbounded. You could sample \(x'\) according to your weight function and then omit the weighting (since it was sampled according to that) to avoid issues like unbounded feature spaces. In general, LIME is a bit subjective in continuous vector feature spaces. For images and text, \(x'\) is formed by masking tokens (words) and zeroing (making black) superpixels. This leads to explanations that should feel quite similar to Shapley values – and indeed you can show LIME is equivalent to Shapley values with some small notation changes.
11.8. Counterfactuals#
A counterfactual is a solution to an optimization problem: find an example \(x'\) that has a different label than \(x\) and as close as possible to \(x\)[WMR17]. You can formulate this like:
In regression settings where \(\hat{f}(x)\) outputs a scalar, you need to modify your constraint to be some \(\Delta\) away from \(\hat{f}(x)\). \(x'\) that satisfies this optimization problem is the counterfactual: a condition that did not occur and would have led to a different outcome. Typically finding \(x'\) is treated as a derivative-free optimization. You can calculate \(\frac{\partial \hat{f}}{\partial x'}\) and do constrained optimization, but in practice it can be faster to just randomly perturb \(x\) until \(\hat{f}(x) \neq \hat{f}(x')\) like a Monte Carlo optimization. You can also use a generative model that can propose new \(x'\) via unsupervised training. See [WSW22] for a universal counterfactual generator for molecules. See [NB20] for a method specifically for graph neural networks of molecules.
Defining distance is an important subjective concern, that we saw above for LIME. A common example for molecular structures is Tanimoto similarity (also known as Jaccard index) of molecular fingerprints/descriptors like Morgan fingerprints [RH10].
Counterfactuals have one disadvantage compared to Shapley values: they do not provide a complete explanation. Shapley values sum to the prediction, meaning we are not missing any part of the explanation. Counterfactuals modify as few features as possible (minimizing distance) and so may omit information about features that still contribute to a prediction. Of course, one advantage of Shapley values is that they are actionable. You can use the counterfactual directly.
11.8.1. Example#
We can quickly implement this idea for our peptide example above. We can define our distance as the Hamming distance. Then the closes \(x'\) would be a single amino acid substitution. Let’s just try enumerating those and see if we can achieve a label swap. We’ll define a function that does a single substitution:
def check_cf(x, i, j):
# copy
x = jnp.array(x)
# substitute
x = x.at[:, i].set(0)
x = x.at[:, i, j].set(1)
return predict(x)
check_cf(sm, 0, 0)
Array(8.861231, dtype=float32)
Then build all possible substitutions with jnp.meshgrid and apply our function over that with vmap. .ravel() makes our array of indices be a single dimensions, so we do not need to worry about doing a complex vmap.
ii, jj = jnp.meshgrid(jnp.arange(sl), jnp.arange(21))
ii, jj = ii.ravel(), jj.ravel()
x = jax.vmap(check_cf, in_axes=(None, 0, 0))(sm, ii, jj)
Now we’ll display the five closest counterfactuals – single amino acid substitutions that flip the prediction from hemolytic to non-hemolytic, sorted by proximity to the decision boundary (logits closest to zero).
from IPython.display import display, HTML
mask = jnp.squeeze(x) < 0
cf_logits = jnp.squeeze(x)[mask]
cf_ii = ii[mask]
cf_jj = jj[mask]
# sort by logit closest to 0 (nearest counterfactuals)
order = jnp.argsort(jnp.abs(cf_logits))[:5]
out = ["<tt>"]
for idx in order:
i, j = int(cf_ii[idx]), int(cf_jj[idx])
out.append(f'{s[:i]}<span style="color:red;">{ALPHABET[j]}</span>{s[i+1:]}<br/>')
out.append("</tt>")
display(HTML("".join(out)))
GHKLWCARGFMTNVTMKHQ
GHKLWRARGFMTNVTMKHQ
GHKLRYARGFMTNVTMKHQ
GHKLWIARGFMTNVTMKHQ
These are the closest counterfactuals – the single amino acid changes that most narrowly flip the model’s prediction. We can see substitutions at several positions can flip the prediction to non-hemolytic.
11.9. Specific Architectures Explanations#
The same principles above apply to GNNs, but there are competing ideas about how best to translate these ideas to work on graphs. See [AZL21] for a discussion of theory of interpretability specifically for GNNs and [YYGJ20] for a survey of the methods available for constructing explanations in GNNs.
NLP is another area where there are specific approaches to constructing explanations and interpretation. See [MRC21] for a recent survey.
11.10. Model Agnostic Molecular Counterfacutal Explanations#
The main challenge associated with counterfactuals in chemistry is the difficulty in computing the derivative in (11.14). Therefore, most methods which focus on this task are specific to model architectures as we saw previously. Wellawatte et. al [WSW22] have introduced a method named Molecular Model Agnostic Counterfactual Explanations (MMACE) to do this for molecules regardless of model architecture.
The MMACE method is implemented in the exmol package. Given a molecule and a model, exmol is able to generate local counterfactual explanations. There are two main steps involved in the MMACE method. First, a local chemical space is expanded around the given base molecule. Next, each sample point is labeled with the user given model architecture. These labels are then used to identify the counterfactuals in the local chemical space. As the MMACE method is model agnostic, exmol package is able to generate counterfactuals for both classification and regression tasks.
Now let’s see how to generate molecular counterfactuals using exmol. In this example, we will train a random forest model which predicts clinical toxicology of molecules. For this binary classification task, we’ll be using the same dataset we used in the Classification chapter presented by the MoleculeNet group [WRF+18].
11.11. Running This Notebook#
Click the above to launch this page as an interactive Google Colab. See details below on installing packages, either on your own environment or on Google Colab
Tip
To install packages, execute this code in a new cell
!pip install exmol jupyter-book matplotlib numpy pandas seaborn sklearn mordred[full] rdkit
# make object that can compute descriptors
calc = mordred.Calculator(mordred.descriptors, ignore_3D=True)
# make subsample from pandas df
molecules = [rdkit.Chem.MolFromSmiles(smi) for smi in toxdata.smiles]
# view one molecule to make sure things look good.
molecules[0]
After importing the data we generate input descriptors with Mordred package.
# Get valid molecules from the sample
valid_mol_idx = [bool(m) for m in molecules]
valid_mols = [m for m in molecules if m]
# Compute molecular descriptors using Mordred
features = calc.pandas(valid_mols, quiet=True, nproc=1)
labels = toxdata[valid_mol_idx].FDA_APPROVED
# Convert to numeric, coercing errors to NaN
features = features.apply(pd.to_numeric, errors="coerce")
# Standardize the features
feat_mean = features.mean()
feat_std = features.std()
features = (features - feat_mean) / feat_std
# we have some nans in features, likely because std was 0
features = features.values.astype(float)
features_select = np.all(np.isfinite(features), axis=0)
features = features[:, features_select]
print(f"We have {len(features)} features per molecule")
We have 1480 features per molecule
In this example, we are using a simple dense neural network classifier implemented with PyTorch. First, let’s train this simple classifier and use it to generate labels for the counterfactuals in exmol. By improving the performance of the trained model, you can expect more accurate results. But the following is example is sufficient to understand the workings of exmol for now.
np.random.seed(0)
torch.manual_seed(0)
random.seed(0)
# Train and test spit
X_train, X_test, y_train, y_test = train_test_split(
features, labels, test_size=0.2, shuffle=True, random_state=0
)
ft_shape = X_train.shape[-1]
# reshape data
X_train = X_train.reshape(-1, ft_shape)
X_test = X_test.reshape(-1, ft_shape)
Now let’s build our model and compile! You can find an in depth introduction to dense models in the Deep Learning Overview chapter.
tox_model = nn.Sequential(
nn.Linear(ft_shape, 32),
nn.ReLU(),
nn.Linear(32, 32),
nn.Linear(32, 1),
nn.Sigmoid(),
)
optimizer = torch.optim.Adam(tox_model.parameters())
criterion = nn.BCELoss()
X_train_t = torch.from_numpy(X_train.astype(np.float32))
y_train_t = torch.from_numpy(y_train.values.astype(np.float32)).unsqueeze(-1)
X_test_t = torch.from_numpy(X_test.astype(np.float32))
y_test_t = torch.from_numpy(y_test.values.astype(np.float32)).unsqueeze(-1)
tox_model.train()
for epoch in range(50):
for i in range(0, len(X_train_t), 32):
xb = X_train_t[i : i + 32]
yb = y_train_t[i : i + 32]
optimizer.zero_grad()
loss = criterion(tox_model(xb), yb)
loss.backward()
optimizer.step()
tox_model.eval()
with torch.no_grad():
preds = tox_model(X_test_t)
accuracy = ((preds > 0.5).float() == y_test_t).float().mean()
print(f"Model accuracy: {accuracy.item():.2%}")
Model accuracy: 92.23%
Seems like our model has a good accuracy!
Now we’ll write a wrapper function that takes in SMILES and/or SELFIES molecule representations and output label predictions from the trained classifier. A detailed description on SELFIES can be found in Deep Learning on Sequences chapter. This wrapper function is given as an input to exmol.sample_space function in exmol to create a local chemical space around a given base molecule. exmol uses Superfast Traversal, Optimization, Novelty, Exploration and Discovery (STONED) algorithm [NPK+21] as a generative algorithm to expand the local space. Given a base molecule, the STONED algorithm randomly mutate SELFIES representations of the molecules. These mutations can be string substitutions, additions or deletions.
def model_eval(smiles, selfies):
molecules = [rdkit.Chem.MolFromSmiles(smi) for smi in smiles]
feat = calc.pandas(molecules, nproc=1)
feat = feat.apply(pd.to_numeric, errors="coerce")
feat = (feat - feat_mean) / feat_std
feat = feat.values.astype(float)
feat = feat[:, features_select]
with torch.no_grad():
preds = tox_model(
torch.from_numpy(
np.nan_to_num(feat).reshape(-1, ft_shape).astype(np.float32)
)
)
return np.round(preds.numpy())
Now we use STONED to sample local chemical space with exmol.sample_space. In this example, we will modify the size of the sample space with num_samples argument. The base molecule selected here is a non-FDA approved molecule.
random.seed(0)
np.random.seed(0)
space = exmol.sample_space("C1CC(=O)NC(=O)C1N2CC3=C(C2=O)C=CC=C3N", model_eval);
Once the sample space is created, we can identify counterfactuals in the local chemical space using exmol.sample_space function. Each counterfactual is a python dataclass that contains additional information.
exps = exmol.cf_explain(space, 2)
exps[1]
Example(smiles='O=C1CCC(N2C(=O)C3=CC=CC(N)=C3C2)C(=S)N1', selfies='[O][=C][C][C][C][Branch1][Branch2][C][=Branch1][C][=S][N][Ring1][#Branch1][N][C][Branch1][#C][C][C][=C][C][=C][Branch1][#Branch1][C][=Ring1][=Branch1][C][Ring1][=Branch2][N][=O]', similarity=0.7966101694915254, yhat=array(1., dtype=float32), index=92, position=array([-6.19248746, -1.64632281]), is_origin=False, cluster=np.int64(-1), label='Counterfactual 1', descriptors=None)
You can easily visualize the generated counterfactuals using the plotting codes in exmol: exmol.sample_space and exmol.sample_space Similarity between the base and counterfactuals is the Tanimoto similarity of ECFP4 fingerprints. Top 3 counterfactuals are the shown here.
exmol.plot_cf(exps, nrows=1)
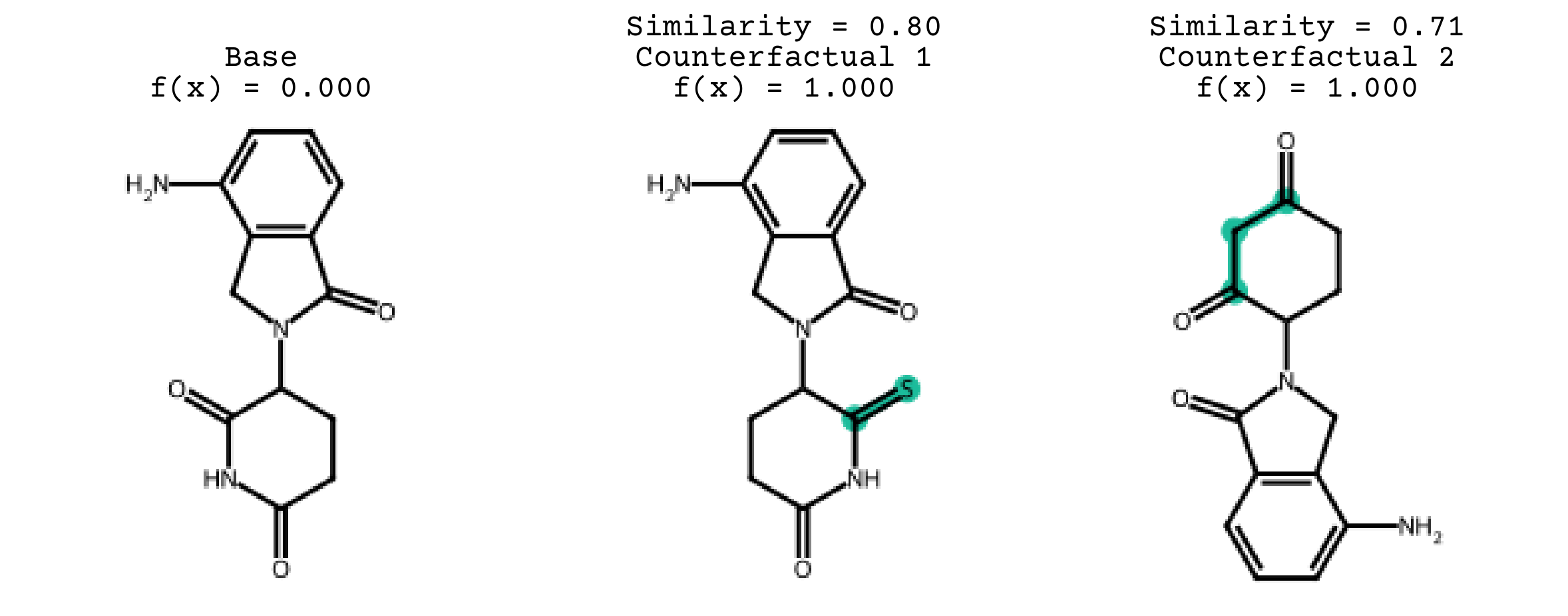
The base molecule which we selected here is NOT FDA approved. By looking at the generated counterfactuals we can conclude that, the heterocyclic group has an impact on the toxicity of the base. Therefore, by altering the heterocylic group, the base molecule might be made non-toxic according to our model. This also shows why counterfactual explanations give actionable insight into how modifications can be made.
We can also visualize the generated chemical space!
exmol.plot_space(space, exps)
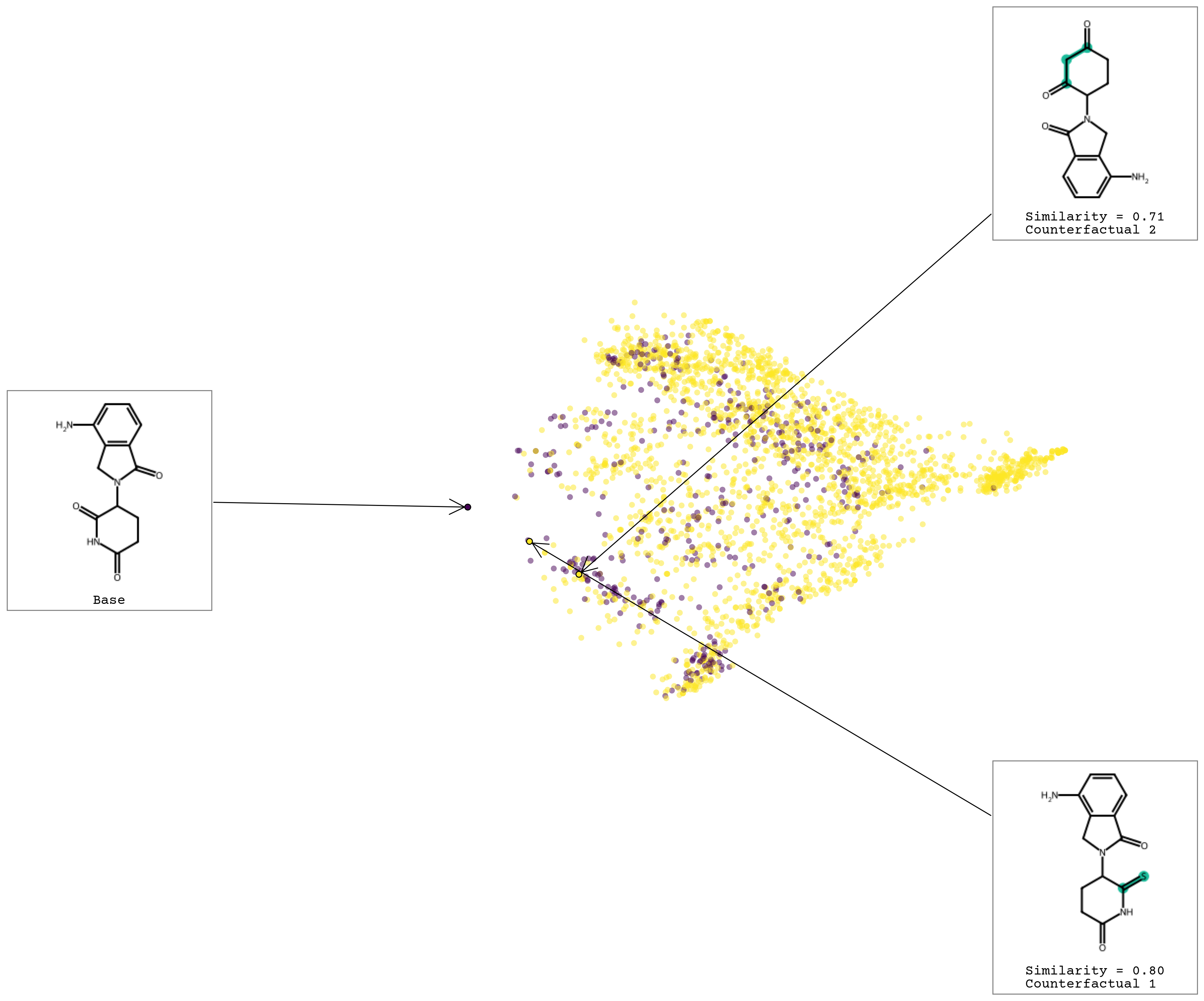
11.12. Chapter Summary#
Interpretation of deep learning models is imperative for ensuring model correctness, making predictions useful to humans, and can be required for legal compliance.
Interpretability of neural networks is part of a broader topic of explainability in AI (XAI), a topic that is in its infancy
An explanation is still ill-defined, but most often is expressed in terms of model features.
Strategies for explanations include feature importance, training data importance, counterfactuals, and surrogate models that are locally accurate,
Most explanations are generated per-example (at inference).
The most systematic but expensive to compute explanations are Shapley values.
Some argue that counterfactuals provide the most intuitive and satisfying explanations, but they may not be complete explanations.
exmolis a software that generate model agnostic molecular counterfactual explanations.
11.13. Exercises#
Computing feature importance requires computing \(\nabla \hat{f}(x)\) - the gradient of the output with respect to the input. Is this the same gradient we compute when training a neural network?
Why might \(\nabla \hat{f}(x)\) be more difficult when the input is a graph (molecule) instead of an image or dense vector?
Some of the attributes of an explanation are if it’s actionable, if it’s faithful (agrees with NN), if it’s sparse, and if it’s complete. Make a table comparing these attributes of explanations generated by training data importance, feature importance, surrogate models, and counterfactual methods.
Can we average feature importances across the whole training dataset to provide a global explanation?
11.14. Cited References#
Zhenqin Wu, Bharath Ramsundar, Evan N Feinberg, Joseph Gomes, Caleb Geniesse, Aneesh S Pappu, Karl Leswing, and Vijay Pande. Moleculenet: a benchmark for molecular machine learning. Chemical science, 9(2):513–530, 2018.
John D Lee and Katrina A See. Trust in automation: designing for appropriate reliance. Human factors, 46(1):50–80, 2004.
Finale Doshi-Velez and Been Kim. Towards a rigorous science of interpretable machine learning. arXiv preprint arXiv:1702.08608, 2017.
Bryce Goodman and Seth Flaxman. European Union regulations on algorithmic decision-making and a “right to explanation”. AI Magazine, 38(3):50–57, 2017.
Organisation for Economic Co-operation and Development. Recommendation of the Council on Artificial Intelligence. 2019. URL: https://legalinstruments.oecd.org/en/instruments/OECD-LEGAL-0449.
Jennifer Blumenthal-Barby. An ai bill of rights: implications for health care ai and machine learning—a bioethics lens. The American Journal of Bioethics, pages 1–3, 2022.
Rich Caruana, Yin Lou, Johannes Gehrke, Paul Koch, Marc Sturm, and Noemie Elhadad. Intelligible models for healthcare: Predicting pneumonia risk and hospital 30-day readmission. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 1721–1730. ACM, 2015.
Tim Miller. Explanation in artificial intelligence: insights from the social sciences. Artificial intelligence, 267:1–38, 2019.
James W Murdoch, Chandan Singh, Karl Kumbier, Reza Abbasi-Asl, and Bin Yu. Interpretable machine learning: definitions, methods, and applications. eprint arXiv, pages 1–11, 2019. URL: http://arxiv.org/abs/1901.04592.
Grégoire Montavon, Wojciech Samek, and Klaus-Robert Müller. Methods for interpreting and understanding deep neural networks. Digital Signal Processing, 73:1–15, 2018.
Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473, 2014.
Mehrad Ansari, Heta A Gandhi, David G Foster, and Andrew D White. Iterative symbolic regression for learning transport equations. arXiv preprint arXiv:2108.03293, 2021.
Lynne Billard and Edwin Diday. Regression analysis for interval-valued data. In Data analysis, classification, and related methods, pages 369–374. Springer, 2000.
Silviu-Marian Udrescu and Max Tegmark. Ai feynman: a physics-inspired method for symbolic regression. Science Advances, 6(16):eaay2631, 2020.
Miles Cranmer, Alvaro Sanchez Gonzalez, Peter Battaglia, Rui Xu, Kyle Cranmer, David Spergel, and Shirley Ho. Discovering symbolic models from deep learning with inductive biases. Advances in Neural Information Processing Systems, 33:17429–17442, 2020.
Geemi P Wellawatte, Aditi Seshadri, and Andrew D White. Model agnostic generation of counterfactual explanations for molecules. Chem. Sci., pages –, 2022. URL: http://dx.doi.org/10.1039/D1SC05259D, doi:10.1039/D1SC05259D.
Marco Tulio Ribeiro, Sameer Singh, and Carlos Guestrin. " why should i trust you?" explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining, 1135–1144. 2016.
Marco Tulio Ribeiro, Sameer Singh, and Carlos Guestrin. Model-agnostic interpretability of machine learning. arXiv preprint arXiv:1606.05386, 2016.
Sandra Wachter, Brent Mittelstadt, and Chris Russell. Counterfactual explanations without opening the black box: automated decisions and the gdpr. Harv. JL & Tech., 31:841, 2017.
Pang Wei Koh and Percy Liang. Understanding black-box predictions via influence functions. In International Conference on Machine Learning, 1885–1894. PMLR, 2017.
Wojciech Samek, Grégoire Montavon, Sebastian Lapuschkin, Christopher J. Anders, and Klaus-Robert Müller. Explaining deep neural networks and beyond: a review of methods and applications. Proceedings of the IEEE, 109(3):247–278, 2021. doi:10.1109/JPROC.2021.3060483.
Christoph Molnar. Interpretable Machine Learning. Lulu.com, 2019. https://christophm.github.io/interpretable-ml-book/.
David Balduzzi, Marcus Frean, Lennox Leary, J. P. Lewis, Kurt Wan-Duo Ma, and Brian McWilliams. The shattered gradients problem: if resnets are the answer, then what is the question? In Doina Precup and Yee Whye Teh, editors, Proceedings of the 34th International Conference on Machine Learning, volume 70 of Proceedings of Machine Learning Research, 342–350. PMLR, 06–11 Aug 2017. URL: http://proceedings.mlr.press/v70/balduzzi17b.html.
Mukund Sundararajan, Ankur Taly, and Qiqi Yan. Axiomatic attribution for deep networks. In International Conference on Machine Learning, 3319–3328. PMLR, 2017.
Daniel Smilkov, Nikhil Thorat, Been Kim, Fernanda Viégas, and Martin Wattenberg. Smoothgrad: removing noise by adding noise. arXiv preprint arXiv:1706.03825, 2017.
Grégoire Montavon, Alexander Binder, Sebastian Lapuschkin, Wojciech Samek, and Klaus-Robert Müller. Layer-Wise Relevance Propagation: An Overview, pages 193–209. Springer International Publishing, Cham, 2019. URL: https://link.springer.com/chapter/10.1007%2F978-3-030-28954-6_10.
Erik Štrumbelj and Igor Kononenko. Explaining prediction models and individual predictions with feature contributions. Knowledge and information systems, 41(3):647–665, 2014.
Rainier Barrett and Andrew D. White. Investigating active learning and meta-learning for iterative peptide design. Journal of Chemical Information and Modeling, 61(1):95–105, 2021. URL: https://doi.org/10.1021/acs.jcim.0c00946, doi:10.1021/acs.jcim.0c00946.
Pascal Sturmfels, Scott Lundberg, and Su-In Lee. Visualizing the impact of feature attribution baselines. Distill, 2020. https://distill.pub/2020/attribution-baselines. doi:10.23915/distill.00022.
Kangway V Chuang and Michael J Keiser. Comment on “predicting reaction performance in c–n cross-coupling using machine learning”. Science, 362(6416):eaat8603, 2018.
Zachary C Lipton. The mythos of model interpretability: in machine learning, the concept of interpretability is both important and slippery. Queue, 16(3):31–57, 2018.
Been Kim, Martin Wattenberg, Justin Gilmer, Carrie Cai, James Wexler, Fernanda Viegas, and others. Interpretability beyond feature attribution: quantitative testing with concept activation vectors (tcav). In International conference on machine learning, 2668–2677. PMLR, 2018.
Danilo Numeroso and Davide Bacciu. Explaining deep graph networks with molecular counterfactuals. arXiv preprint arXiv:2011.05134, 2020.
David Rogers and Mathew Hahn. Extended-connectivity fingerprints. Journal of chemical information and modeling, 50(5):742–754, 2010.
Chirag Agarwal, Marinka Zitnik, and Himabindu Lakkaraju. Towards a rigorous theoretical analysis and evaluation of gnn explanations. arXiv preprint arXiv:2106.09078, 2021.
Hao Yuan, Haiyang Yu, Shurui Gui, and Shuiwang Ji. Explainability in graph neural networks: a taxonomic survey. arXiv preprint arXiv:2012.15445, 2020.
Andreas Madsen, Siva Reddy, and Sarath Chandar. Post-hoc interpretability for neural nlp: a survey. arXiv preprint arXiv:2108.04840, 2021.
AkshatKumar Nigam, Robert Pollice, Mario Krenn, Gabriel dos Passos Gomes, and Alán Aspuru-Guzik. Beyond generative models: superfast traversal, optimization, novelty, exploration and discovery (stoned) algorithm for molecules using selfies. Chem. Sci., 12:7079–7090, 2021. URL: http://dx.doi.org/10.1039/D1SC00231G, doi:10.1039/D1SC00231G.