6. Deep Learning Overview#
Deep learning is a category of machine learning. Machine learning is a category of artificial intelligence. Deep learning is the use of neural networks to do machine learning, like classify and regress data. This chapter provides an overview and we will dive further into these topics in later chapters.
Audience & Objectives
This chapter builds on Regression & Model Assessment and Introduction to Machine Learning. After completing this chapter, you should be able to
Define deep learning
Define a neural network
Connect the previous regression principles to neural networks
There are many good resources on deep learning to supplement these chapters. The goal of this book is to present a chemistry and materials-first introduction to deep learning. These other resources can help provide better depth in certain topics and cover topics we do not even cover, because I do not find them relevant to deep learning (e.g., image processing). I found the introduction the from Ian Goodfellow’s book to be a good intro. If you’re more visually oriented, Grant Sanderson has made a short video series specifically about neural networks that give an applied introduction to the topic. DeepMind has a high-level video showing what can be accomplished with deep learning & AI. When people write “deep learning is a powerful tool” in their research papers, they typically cite this Nature paper by Yann LeCun, Yoshua Bengio, and Geoffery Hinton. Zhang, Lipton, Li, and Smola have written a practical and example-driven online book that gives each example in Tensorflow, PyTorch, and MXNet. You can find many chemistry-specific examples and information about deep learning in chemistry via the excellent DeepChem project. Finally, some deep learning package provide a short introduction to deep learning via a tutorial of its API: Keras, PyTorch.
The main advice I would give to beginners in deep learning are to focus less on the neurological inspired language (i.e., connections between neurons), and instead view deep learning as a series of linear algebra operations where many of the matrices are filled with adjustable parameters. Of course nonlinear functions (activations) are used to join the linear algebra operations, but deep learning is essentially linear algebra operations specified via a “computation network” (aka computation graph) that vaguely looks like neurons connected in a brain.
nonlinearity
A function \(f(\vec{x})\) is linear if two conditions hold:
for all \(\vec{x}\) and \(\vec{y}\). And
where \(s\) is a scalar. A function is nonlinear if these conditions do not hold for some \(\vec{x}\).
6.1. What is a neural network?#
The deep in deep learning means we have many layers in our neural networks. What is a neural network? Without loss of generality, we can view neural networks as 2 components: (1) a nonlinear function \(g(\cdot)\) which operates on our input features \(\mathbf{X}\) and outputs a new set of features \(\mathbf{H} = g(\mathbf{X})\) and (2) a linear model like we saw in our Introduction to Machine Learning. Our model equation for deep learning regression is:
One of the main discussion points in our ML chapters was how arcane and difficult it is to choose features. Here, we have replaced our features with a set of trainable features \(g(\vec{x})\) and then use the same linear model as before. So how do we design \(g(\vec{x})\)? That is the deep learning part. \(g(\vec{x})\) is a differentiable function composed of layers, which are themselves differentiable functions each with trainable weights (free variables). Deep learning is a mature field and there is a set of standard layers, each with a different purpose. For example, convolution layers look at a fixed neighborhood around each element of an input tensor. Dropout layers randomly inactivate inputs as a form of regularization. The most commonly used and basic layer is the dense or fully-connected layer.
A dense layer is defined by two things: the desired output feature shape and the activation. The equation is:
where \(\mathbf{W}\) is a trainable \(F \times D\) matrix, where \(D\) is the input vector (\(\vec{x}\)) dimension and \(F\) is the output vector (\(\vec{h}\)) dimension, \(\vec{b}\) is a trainable \(F\) dimensional vector, and \(\sigma(\cdot)\) is the activation function. \(F\), the number of output features, is an example of a hyperparameter: it is not trainable but is a problem dependent choice. \(\sigma(\cdot)\) is another hyperparameter. In principle, any differentiable function that has a domain of \((-\infty, \infty)\) can be used for activation. However, the function should be nonlinear. If it were linear, then stacking multiple dense layers would be equivalent to one-big matrix multiplication and we’d be back at linear regression. So activations should be nonlinear. Beyond nonlinearity, we typically want activations that can “turn on” and “off”. That is, they have an output value of zero for some domain of input values. Typically, the activation is zero, or close to, for negative inputs.
The most simple activation function that has these two properties is the rectified linear unit (ReLU), which is
6.1.1. Universal Approximation Theorem#
One of the reasons that neural networks are a good choice at approximating unknown functions (\(f(\vec{x})\)) is that a neural network can approximate any function with a large enough network depth (number of layers) or width (size of hidden layers). There are many variations of this theorem – infinitely wide or infinitely deep neural networks. For example, any 1 dimensional function can be approximated by a depth 5 neural network with ReLU activation functions with infinitely wide layers (infinite hidden dimension) [LPW+17]. The universal approximation theorem shows that neural networks are, in the limit of large depth or width, expressive enough to fit any function.
6.1.2. Frameworks#
Deep learning has lots of “gotchas” – easy to make mistakes that make it difficult to implement things yourself. This is especially true with numerical stability, which only reveals itself when your model fails to learn. In this example, we’ll use PyTorch which has stronger opinions than JAX and lends itself to more concise code for writing neural networks.
6.1.3. Discussion#
When it comes to introducing deep learning, I will be as terse as possible. There are good learning resources out there. You should use some of the reading above and tutorials put out by PyTorch or others to get familiar with the concepts of neural networks and learning.
6.2. Revisiting Solubility Model#
We’ll see our first example of deep learning by revisiting the solubility dataset with a two layer dense neural network.
6.3. Running This Notebook#
Click the above to launch this page as an interactive Google Colab. See details below on installing packages.
Tip
To install packages, execute this code in a new cell.
!pip install dmol-book
If you find install problems, you can get the latest working versions of packages used in this book here
import pandas as pd
import numpy as np
import torch
from torch import nn
from torch.utils.data import TensorDataset, DataLoader
import matplotlib.pyplot as plt
6.3.1. Load Data#
We download the data and load it into a Pandas data frame and then standardize our features as before.
# soldata = pd.read_csv('https://dataverse.harvard.edu/api/access/datafile/3407241?format=original&gbrecs=true')
# had to rehost because dataverse isn't reliable
soldata = pd.read_csv(
"https://github.com/whitead/dmol-book/raw/main/data/curated-solubility-dataset.csv"
)
# Identify feature columns
features_start_at = list(soldata.columns).index("MolWt")
feature_names = soldata.columns[features_start_at:]
# Standardize features
soldata[feature_names] = (
soldata[feature_names] - soldata[feature_names].mean()
) / soldata[feature_names].std()
6.4. Prepare Data for Training#
The deep learning libraries simplify many common tasks, like splitting data and building layers. This code below builds our dataset from numpy arrays. The reason we cannot use numpy directly is that we need to be able to move our data to a GPU (or the more abstract term “accelerator”) and then back to the CPU.
X = torch.tensor(soldata[feature_names].values, dtype=torch.float32)
y = torch.tensor(soldata["Solubility"].values, dtype=torch.float32).view(-1, 1)
# Split into train/test
N = len(soldata)
test_N = int(0.1 * N)
X_test, y_test = X[:test_N], y[:test_N]
X_train, y_train = X[test_N:], y[test_N:]
train_ds = TensorDataset(X_train, y_train)
test_ds = TensorDataset(X_test, y_test)
train_loader = DataLoader(train_ds, batch_size=16, shuffle=True)
test_loader = DataLoader(test_ds, batch_size=16, shuffle=False)
Notice that we used split our dataset into two pieces and created batches of data. We didn’t include a validation dataset, since we’re not exploring hyperparameters in this example — just training and then a test.
6.5. Neural Network#
Now we build our neural network model. In this case, our \(g(\vec{x}) = \sigma\left(\mathbf{W^0}\vec{x} + \vec{b}\right)\). We will call the function \(g(\vec{x})\) a hidden layer. This is because we do not observe its output. Remember, the solubility will be \(y = \vec{w}g(\vec{x}) + b\). We’ll choose our activation, \(\sigma(\cdot)\), to be tanh and the output dimension of the hidden-layer to be 32. The choice of tanh is empirical — there are many choices of nonlinearity and they are typically chosen based on efficiency and empirical accuracy. You can read more about this PyTorch API here, however you should be able to understand the process from the function names and comments.
# Define model
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Now we put the layers into a sequential model
# We only need to define the output dimension - 32.
# Last layer - which we want to output one number
# the predicted solubility.
model = nn.Sequential(
nn.Linear(X.shape[1], 32),
nn.Tanh(),
nn.Linear(32, 1)
).to(device)
# our model is complete
# Try out our model on first few datapoints
model(X[:3])
tensor([[0.2727],
[0.1036],
[0.1161]], grad_fn=<AddmmBackward0>)
We can see our model predicting the solubility for 3 molecules above. This model has completely random parameters, so these numbers aren’t actually good predictions. However, just making sure your model outputs data in the correct dimension is a good sanity check before starting to train.
At this point, we’ve defined how our model structure should work and it can be called on data. Now we need to train it!
We start by defining our optimizer, just gradient descent in this example, and a loss function. Our loss is just the mean squared error, which is a good loss for regression problems.
loss_fxn = nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
Now we write our training loop. I’ve put comments on the key steps below, but it is relatively straightforward: iteratively update the model weights based on new data batches.
# Training loop
for epoch in range(50):
# some layers in deep learning models behave differently
# when training, so we set the training mode
model.train()
running_loss = 0.0
# load a batch and put it on the GPU/accelerator
for xb, yb in train_loader:
xb, yb = xb.to(device), yb.to(device)
# in pytorch, we must explicitly zero the parameter gradients
optimizer.zero_grad()
preds = model(xb)
loss = loss_fxn(preds, yb)
# the backward does the actual back-prop from loss to individual parameter gradients
loss.backward()
# this actually applies the gradient update
optimizer.step()
running_loss += loss.item() * xb.size(0)
epoch_loss = running_loss / len(train_loader.dataset)
if (epoch + 1) % 10 == 0:
print(f"Epoch {epoch+1:02d} | Train MSE: {epoch_loss:.4f}")
This is a small dataset, so you should see quick training.
50 epochs is actually quite a bit - that means the model saw each data point 50 times. In a pratical setting, we would want to assess for overfitting a bit more carefully here.
For reference, we got a loss about as low as 3 in our previous work. It was also much faster, thanks to the optimizations. Now let’s see how our model did on the test data
# get model predictions on test data and get the true labels
# tell the model it is no longer training time
# so layers that have different behavior in training
# can adjust
model.eval()
# this tells pytorch we aren't doing gradients
# and then you can call `.numpy()` without pytorch
# panicking about that affecting its ability to compute gradients
with torch.no_grad():
yhat = []
for xb, _ in test_loader:
xb = xb.to(device)
preds = model(xb).cpu()
yhat.append(preds)
# squeeze to remove extra dimensions
yhat = torch.cat(yhat).squeeze().numpy()
test_y = y_test.squeeze().numpy()
plt.figure()
plt.plot(test_y, yhat, ".")
plt.plot(test_y, test_y, "-", linewidth=1)
plt.xlabel(r"Measured Solubility $y$")
plt.ylabel(r"Predicted Solubility $\hat{y}$")
plt.text(
min(test_y) + 1,
max(test_y) - 2,
f"correlation = {np.corrcoef(test_y, yhat)[0,1]:.3f}",
)
plt.text(
min(test_y) + 1,
max(test_y) - 3,
f"RMSE = {np.sqrt(np.mean((test_y - yhat)**2)):.3f}",
)
plt.show()
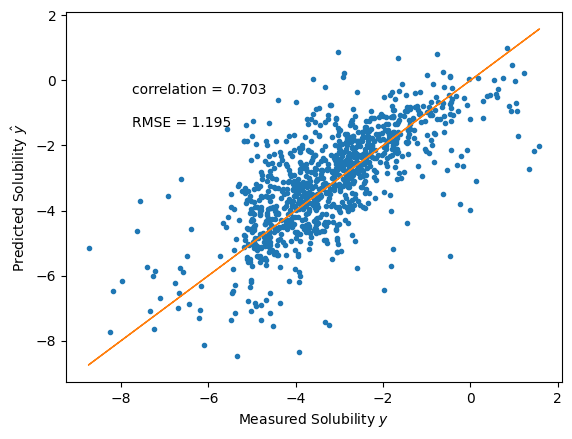
This performance is better than our simple linear model.
6.6. Exercises#
Make a plot of the ReLU function. Prove it is nonlinear.
Try increasing the number of layers in the neural network. Discuss what you see in context of the bias-variance trade off
Show that a neural network would be equivalent to linear regression if \(\sigma(\cdot)\) was the identity function
What are the advantages and disadvantages of using deep learning instead of nonlinear regression for fitting data? When might you choose nonlinear regression over deep learning?
6.7. Chapter Summary#
Deep learning is a category of machine learning that utilizes neural networks for classification and regression of data.
Neural networks are a series of operations with matrices of adjustable parameters.
A neural network transforms input features into a new set of features that can be subsequently used for regression or classification.
The most common layer is the dense layer. Each input element affects each output element. It is defined by the desired output feature shape and the activation function.
With enough layers or wide enough hidden layers, neural networks can approximate unknown functions.
Hidden layers are called such because we do not observe the output from one.
Using libraries such as TensorFlow, it becomes easy to split data into training and testing, but also to build layers in the neural network.
Building a neural network allows us to predict various properties of molecules, such as solubility.
6.8. Cited References#
Zhou Lu, Hongming Pu, Feicheng Wang, Zhiqiang Hu, and Liwei Wang. The expressive power of neural networks: a view from the width. In Proceedings of the 31st International Conference on Neural Information Processing Systems, 6232–6240. 2017.